가끔 약을 먹어야 하는 사람에게는 모를 수 있지만 매일 약을 먹어야 하는 사람들은 오늘 아침에 약을 먹었는지 안 먹었는지 잊을 때가 있다. 잠에서 깨어 습관적으로 먹고 잠들었다가 꿈에서 먹었는지 진짜 먹은 것인지 모를 때도 있다. 그래서 요일별로 7개의 칸이 나누어진 약 상자에 넣어두고 오늘 요일에 해당하는 약이 있는지 없는지를 확인하고 먹을 때도 있다. 저녁 약을 먹어야 한다면 비슷하다. 저녁에 약을 먹었는지 아닌지 알지 못할 때가 있다. 요일별로 나누어진 약상자를 가지고 다니면 좋지만 일주일에 한번 일주일 약을 챙기는 것도 귀찮을 때가 있다. 요일 별 상자도 좋지만 저녁에 먹어야 하는 약이 4개 정도라면 4칸 혹은 아예 나누어지지 않은 약 상자를 가지고 다니면서 오늘 저녁 약을 먹었는지 아닌지 확인할 수 있는 방법은 없을지 생각해 본다.

습관적으로 매일 아침, 저녁으로 먹어야 하는 사람에게 약을 먹으라고 알람을 울리는 것도 좋은 방법이다. 지금 하고 있는 일이 있어서 나중에 먹어야 겠다 마음먹고는 잊어버리는 경우도 있고 방금 전에 먹었는지 아닌지도 확실하지 않을 때도 있다. 요일별로 나누어진 약 상자라면 오늘 요일을 확인하면 되지만 만약 요일별로 있지 않을 때도 방법이 있다. 약 상자에 약을 넣을 때 7의 배수로 넣는 것이다. 7개, 14개 약이 작다면 21개 이런 식으로 넣는다. 저녁 약을 잘 먹어오다가 목요일 저녁에 약을 먹었는지 아닌지 모르겠다면 남아 있는 약을 세어 보고 만약 3개, 10개가 남았다면 먹은 것이고 4개, 11개가 남았다면 목요일 저녁에 약을 아직 먹지 않은 것이다.
알약의 개수는 데이터이다. 몇개가 남았는지는 우리에게는 그냥 주어지는 데이터일 뿐이지만 요일 정보와 결합이 될 때 우리가 무엇을 했는지 아닌지를 알 수 있는 개인에게 관련된 정보가 되는 것이다. 데이터는 단순한 숫자 혹은 문자열일 수 있지만 데이터가 개인의 상황 혹은 조건과 결합이 되면 개인에게 의미가 있는 정보가 될 수 있다. 알약의 예에서 3개, 10개가 남은 것은 단순한 데이터이지만 이것이 목요일이라는 정보 그리고 매일 약을 먹는 사람이라는 상황이 결합이 되면 개인이 약을 저녁에 먹었는지 아닌지 알 수 있게 된다. 데이터란 무엇이며 데이터가 가지는 힘, 그리고 그 힘이 우리에게 어떻게 다시 영향을 줄 수 있는지를 이해하는 것은 정보의 바다에서 최소한 익사하지 않기 위한 구명정이라 생각하게 된다.
Datum Era ...
데이터는 번역하면 단순하게 자료로 번역되지만 단순히 조금 부족한 느낌이 들기 때문에 외래어로 데이터로 사용할 것이다. 데이터의 어원은 라틴어 datum 그리고 datum 은 '주다'는 뜻의 dare 에서 유래되었다. 무엇인가를 설명하기 위한 기초적인 자료 누군가를 설득시키기 위해 필요한 모든 자료들을 데이터라고 말하고 수리적으로 계산하기 위한 대상이기도 하다. 예를 들어 건물의 높이를 측정하기 위해서 높이가 몇 m 이고 넓이는 어느정도라고 말하는 대부분의 숫자들은 우리가 건물의 규모를 이해하기 위해 필요한 숫자들이다. 그리고 그 숫자를 통해서 건물의 가치가 어떻게 된다와 같은 논리적인 내용을 이어가기 위한 내용들이다. 쉽게 이해할 수 있지만 실제로 데이터는 숫자 그리고 간단하게 교환될 수 있는 문자 정도로 구성되어 있다. 대부분이 숫자이고 컴퓨터의 발달로 문서 내용이나 사진, 음원 등과 같은 거의 모든 내용들은 0, 1 로 이루어진 숫자로 표현이 가능하게 되었다.
간단하게 모든 데이터는 숫자로 표현할 수 있게 되었다고 설명할 수 있지만 중요한 것은 이렇게 표현된 숫자들이 우리의 삶에서 중요한 의사결정을 하는데 무엇을 평가하거나 계획하는데 필요한 숫자들이라는 점이다. 조금 과장해서 이 세상이 0, 1 로 이루어졌다고 할 수 없지만 0, 1에 의해 세상이 움직일 수 있다고는 말할 수 있을 것이다. 영화 매트릭스 (1999) 는 우리가 살고 있는 세상도 실제로 존재하는 곳이 아닌 데이터로 이루어진 곳이며 우리는 그것을 인식하지 못하고 살아갈지 모른다고 이야기해주었다. 소위 빨간약 / 파란약의 선택에서 파란약을 먹는다면 예전처럼 살던 모습대로 살아가고 빨간약을 먹게 된다면 매트릭스 그리고 데이터가 만들어 놓은 실제 세상에서 싸우게 되는 것이다. 파란약을 먹고 망각과 평온의 세상을 살게 될지 빨간약을 먹고 자각과 고통의 세상을 살 것인지 선택하게 된다. 매트릭스처럼 모든 것이 데이터로 이루어진 세상에 허구로 살아가는 존재는 아니지만 우리가 무의식 속에서 흘러가는 수많은 데이터들을 인식하게 되는 순간 세상은 우리가 생각하는 것만큼 데이터의 주인은 우리가 아니라는 사실을 알게 될 것이다. 그래서 영화 매트릭스가 우리에게 전해주고 싶은 이야기는 허구 / 실체의 구별이 아니라 우리가 얼마나 많은 데이터를 만들어 내고 개인정보들이 흘러 나오지만 우리는 그 데이터의 흐름을 인식하지 못하고 있는지 알려주고 싶었는지 모른다.
다시 정리하자면 데이터는 의미없는 숫자나 정보까지도 모두 다 포함한다. 그러나 데이터가 조건 condition 과 상황 circumstance 과 결합이 되면 개인정보가 될 수 있다. 앞서 설명한 것처럼 약의 개수는 단순한 데이터지만 약을 매일 먹는다는 조건과 약을 7의 배수로 상자에 넣은 상황이 결합되면 오늘 약을 먹었는지 아닌지 알 수 있게 된다. 우리가 민감하게 생각하는 개인정보 privacy 란 데이터와 조건, 상황이 포함된 결과물이다. 모든 데이터가 개인정보는 아니지만 모든 개인정보는 데이터라고 말할 수 있다. 개인정보의 저장, 전달 및 가공의 단계를 고려해서 우리가 만든 데이터들이 얼마나 많은 개인정보로 전달 가공될 수 있는지 생각해 볼 필요가 있다.
Data Tsunami ...
개인은 얼마나 많은 데이터를 만들고 있고 내가 만든 데이터는 모두 나의 개인정보가 되는지 그리고 내가 만들지 않은 데이터가 나의 개인정보가 될 수 있는가 고민하지 않는다. 특별히 내가 만드는 데이터가 많지 않을 것이라는 생각과 함께 내가 만든 데이터가 중요하지 않을 것이라고 생각하기 때문이기도 하다. 그러나 결론부터 말하면 데이터의 가치는 중요하지 않다. 다시 강조하지만 데이터가 어떻게 개인정보를 포함해서 어떻게 중요한 정보가 될 수 있는지는 조건과 상황에 따라서 달라진다. 냉전시대 인터넷이 중요하지 않은 시절에는 인터넷을 연결할 수 있는 정보 그리고 관련된 데이터는 분명 중요하다 못해 극비 데이터였지만 이제는 누가 가지라고 해도 쓸모없는 데이터이다.
가장 많은 실수 중 하나는 데이터를 만들 때부터 중요한 데이터 / 중요하지 않은 데이터와 같이 가치 판단을 해서 선별해서 만들려고 한다는 점이다. 그러나 데이터는 많으면 많을수록 좋고 데이터가 가지는 조건과 상황을 같이 고려한다면 우리에게 중요한 정보들이 만들어 질 수 있다. 따라서 데이터의 초기 생성 단계부터 데이터의 가치를 판단한다는 것은 다이아몬드 원석을 찾으면서 반짝이는 것만을 찾는 것과 비슷하다. 컴퓨터나 전자 기기가 많이 보급되지 않은 시절에는 어떤 데이터를 수집할 것인지 선택해야지만 한정된 자원으로 원하는 데이터를 모을 수 있었지만 이제는 그럴 이유가 없어졌다. 움직이지 않아도 내 곁에 있는 핸드폰은 끊임없이 내가 어디에 있고 (정확하게 핸드폰이 어디에 있고) 필요하다면 어떤 소리가 나는지 어떤 뉴스가 전달되는지 끊임없이 데이터를 주고 받는다. 그리고 그 데이터 안에는 이미 가공되어 가치가 있다고 생각되는 정보들도 많이 전달된다. 예를 들어 가치있다고 믿는 뉴스가 나에게 전달되었을 때 읽지도 않고 그냥 지워버렸다면 지워버리는 행동 안에도 사용자는 아주 잠깐동안 읽었다 (실제로는 읽지 않았다) 지워버렸다는 데이터가 발생하고 이 데이터를 사용자는 해당 뉴스에 대해서 관심이 별로 없다는 정보를 얻을 수 있다. 반복적으로 스포츠 뉴스에 대해서 읽지 않고 지워버린다는 행동들이 데이터로 모이게 된다면 해당 사용자는 스포츠에 대한 관심이 크지 않다는 정보를 얻게 된다.

이처럼 우리는 별 생각없이 움직이고 반응하고 행동하지만 이 모든 행동들은 핸드폰과 같이 수많은 센서들이 있는 기기를 통해서 상상하지도 못하는 수많은 데이터들이 만들어진다. 다른 예를 들어보자. 반대로 거의 모든 차량에 있는 영상기록장치 (블랙박스) 는 데이터인가 개인정보인가 묻는다면 거의 대부분은 개인정보라고 대답할 수 있지만 해당 영상기록이 누구의 것인지 모르게 인터넷에 그냥 떠돌아 다닌다면 그것은 개인정보이기 보다는 그냥 단순한 데이터라고 말하는 것이 더 정확할 것이다. 누군지 알 수 없고 그리고 특별한 사고 기록이 있어서 더 이상 알 필요가 없이 정상적으로 잘 주행한 영상기록이라면 개인정보의 가치를 가지지 않을 것이다. 다만 대부분의 영상기록 데이터는 누구의 것이라 내용을 알기 때문에 바로 '누구의 것'이라는 소유의 조건이 포함되어 개인정보가 되는 것이다.
Privacy manufacturer ...
소위 음란물 영상에서 사람들이 중요하게 생각하는 것이 무엇일까? 이 질문에 정확하게 대답하기 위해서는 음란물을 탐독하고 그들의 세상에서 접근하는 것이 중요하지만 그렇게 하고 있다고 해도 그렇고 그것을 위해 탐독한다고 해도 좀 그렇다. 간접적으로 알 수 있는 방법은 사람들이 많이 찾는 제목이나 내용을 통해서 찾아보는 것이다. 개인의 성적 흥분만을 위해서 음란물이 필요하다면 누군지 알 수 없이 알몸만 나온 영상으로 성적 행위를 보여주면 될 것같은데 음란물을 탐독하는 제목은 이상하게 등장인물에 더욱 집중하는 경향을 보인다. 인종별로 분류하거나 얼굴이 나왔는지 심지어 영상에서는 알 수 없는 두사람의 관계에 대해서도 친절하게 설명한다. 음란물의 가장 큰 문제는 결국 영상 데이터가 누구인지 특정될 identify 수 있는 개인정보가 된다는 점과 정확한지 알 수 없는 그리고 알 필요도 없는 수많은 잘못된 조건과 상황이 결합되어 막기 힘든 개인정보가 되어버린다는 점이다. 음란물이 사회적 문제가 된다는 공감대를 가지는 가장 큰 이유는 개인정보 뿐만 아니라 그 개인정보가 전달 속도와 힘이 무섭다는 점이다.
음란물은 아니지만 우리는 수많은 개인정보를 만들어 내고 있다. 개인은 단순히 데이터를 만들고 있다고 생각하지만 인터넷은 충분히 그런 데이터를 개인정보로 만들고 있다. 우리가 사용하는 많은 인터넷 서비스들은 다른 의미에서 우리가 의미없이 만들어내는 데이터들을 개인정보로 가공하는 공장과도 같다. 예를 들어 인스타그램 Instagram 에 수많은 사진들을 올린다. 올리는 순간에는 단순히 데이터지만 개인의 계정을 통해서 전달되기 때문에 자연스럽게 바로 개인정보가 된다. 반대로 개인을 특정하기 힘든 광고 목적으로 만들어진 계정에서 올린 데이터라면 개인정보라고 보기 어려운 데이터도 존재할 것이다. 자기 가족의 사진을 올리는 경우를 자주 볼 수 있다. 공개로 올린 단란한 사진들 속에는 누가 아버지고 누가 어머니고 누가 자식인지 모두 보여준다. 나쁜 맘을 먹는다면 아이들을 납치하고 정확하게 몸값을 요구해야 하는 부모가 누구인지 알 수도 있고 아버지를 납치하기 위해 자식이나 부인에게 가족여행 당첨되었다며 유인할 수도 있을지 모른다. 심지어 인스타그램을 포함한 많은 소셜 미디어는 태그를 통해서 더 특정할 수 있다. 예를 들어 #지역맘 과 같이 특정 지역이 포함된 그리고 육아를 시작한 인물들을 찾아내기 쉬울 뿐만 아니라 오히려 그렇게 찾도록 스스로 태그를 올리기도 한다. 마음만 먹는다면 특정 지역에 육아에 몰두하는 엄마를 찾을 수도 있고 자식이 어떻게 생겼는지도 쉽게 파악할 수 있다.

반대로 자신이 소비하고 즐기는 생활 수준을 자랑하고 싶을 수도 있다. 물론 그렇게 자랑하는 것이 나쁘다고 할 수 없지만 자랑하고 싶은 소비 수준뿐만 아니라 삶의 동선까지도 쉽게 노출시킨다. 어느정도 그런 부분을 노출시킬 수 밖에 없기도 하고 광고나 홍보 목적으로 사용한다면 적극 노출되게 해야겠지만 개인의 삶까지도 광범위하게 노출시켜야 하는지 의문스럽다. 오히려 그렇게 노출되는 범위는 결국 피해볼 수 있는 위험을 높여주기 때문이다. 미국의 정보기관에 들어간 기쁨에 자신의 계정에 정보기관 신분증을 공개된 계정으로 올린 정말 이해할 수 없는 사람이 있었다. 물론 그 기쁨과 함께 기관 신분증 이미지를 올린 것만으로 바로 해고되었지만 종종 출입증과 같이 중요한 정보를 가지는 데이터를 아무렇지 않게 올리는 사람들이 있다. 친절하게 자신의 사진이나 이름 정도는 지우고 올리기에 개인정보가 아닌 단순히 데이터라고 할 수 있지만 동일 기관에 대한 출입증 이미지만 모아보면 위조 신분증을 만들 수 있는 좋은 데이터가 될 것이다.
개인정보의 노출 위험성을 인식하고 조심하는 대표적인 경우가 택배 도착의 기쁨을 알리는 사진일 것이다. 열심히 자신의 주소, 이름 등 개인정보가 될 것 같은 부분을 열심히 지우고 올리지만 정작 바코드는 너무도 선명하게 보인다. 바코드를 읽어서 해당 택배 회사에서 송장번호로 검색하면 생각보다 많은 개인정보가 나온다는 것을 알게 된다. 열심히 숨겨온 개인의 주소도 노출될 수 있고 개인이 올리는 지역의 정보을 모아보면 개인의 동선 뿐만 아니라 조금 더 노력하게 된다면 개인 거주지까지도 알아낼 수 있다. 가끔 #삭제예정 이라는 태그로 올라오는 공개 사진들을 보면 자신의 계정에서 삭제되면 정말로 인터넷에서 삭제될 것이라고 믿는지 모르겠다. 여러가지 목적이 있지만 이처럼 인스타그램에서 공개된 사진들이 거의 실시간으로 수집된다. 그래서 #삭제예정 이지만 이미 #공개완료 라는 사실도 인식해야 한다.
What machine does better ...
인공지능 Artificial intelligence 이 관심의 중심에 놓이면서 항상 재미처럼 붙는 주제가 바로 인공지능이 빼앗아갈 인간의 직업이다. 어떤 직업은 인공지능에 의해서 사라지게 될 것이다. 어떤 분야는 인공지능이 인간보다 더 잘할 것이라고 예상하지만 아직 제대로 존재하지 않는 인공지능의 직업을 사라지게 할 것이라고 말하기도 한다. 인간의 관심사에는 어떤 직업 job 이 사라지게 되는지가 중요할 것이다. 인공지능의 시대에는 선택하지 말아야 하는 혹은 선택할 수 없는 직업이라고 생각하기 때문이다. 그러나 인공지능 더 현실적으로 보아서 직업의 관점이 아니라 작업 work 더 구체적으로는 작업내용 workflow 의 관점에서 생각해 볼 필요가 있다. 알파고 AlphaGo 가 보여준 것처럼 인간과 기계의 대결에서 누가 이기는지가 중요한 것이 아니라 기계가 인간보다 더 잘하는 내용을 찾아야 하는 것이다. 그리고 기계가 잘하는 작업내용을 통해서 기계에게 양보해야 할 내용은 무엇인지 인간이 계속 해야만 하는 것이 무엇인지 결정해야 한다.
우선 인간의 의사 결정 decision making 과정이 정말 논리적이고 합리적인지 생각해 보자. 회사의 최고 경영자나 나라의 지도자 아주 사소한 결정을 내려야 하는 위치에 있는 어떤 사람들도 자신의 선택이 항상 합리적이라 모든 이들이 이해하고 따를 수 있기를 바라지만 현실의 많은 부분은 그렇지 않다. 처음부터 인간의 의사 결정 과정이 정말 합리적인지 의심해야 한다. 많은 자료를 모으고 어떤 결정이 가장 최선의 결과를 얻을 수 있는지에 대해서 고민하지만 종종 인간의 결정은 아주 사소한 그리고 감정적인 선택을 하게 되는 경우를 종종 보게 된다. 단적으로 모든 인간이 객관적 자료에 의해 합리적으로 모두 결정하게 된다면 누군가를 설득시키는 작업도 회사에서 마케팅의 역할도 크게 필요하지 않을 것이다. 그러나 합리적 판단을 위한 충분한 자료 혹은 데이터를 얻지 못하는 경우도 존재하고 잘못된 데이터 혹은 목적을 가지는 데이터를 통해서 잘못된 선택을 하게 되기도 한다. 경영을 잘하기 위해서 도입되는 경영정보시스템 MIS: Management Information Systems 부터 의사결정지원 Decision making support 시스템은 사실상 인간이 좀 더 합리적으로 판단하기 위해서 필요한 데이터를 어떻게 잘 모을 수 있는지 도와주는 것이다. 그러나 결국 마지막 선택은 그 모든 데이터와 분석에도 불구하고 인간이 한다.
그래서 모든 직업에서 이루어지는 구체적인 작업내용 workflow 상에서 데이터를 모으고 분석하는 단계는 기계가 인간보다 더 잘할 수 있다고 생각했다. 그러나 현실적으로 그 모든 데이터들은 대부분 인간이 입력해야 하기 때문에 어떤 데이터를 입력하게 되는지도 인간의 의도 bias 가 들어가게 되었다. 그래서 인간은 데이터를 입력하기 보다는 무엇인가 가치판단이 포함되어 선택된 정보가 입력되기 쉬었다. 즉, 인간에게 가치있어 보이는 정보를 만들기 위한 수많은 데이터들은 인간이 보고, 듣고 (혹은 느끼고) 판단하고 필요한 정보로 만들어서 가공해서 만드는 작업을 중요하게 생각했다. 수많은 데이터가 아닌 인간이 한번 분석해준 정보로 판단하고 싶은 것이다.
예를 들어 '요즘 유행하는 혹은 앞으로 유행할 패션은 어떤 것인가?' 라는 질문을 받게 된다면 패션 종사자들은 사람들이 입고 다니는 옷들부터 전문가들의 의견 등 다양한 데이터 혹은 정보를 얻어 결론을 내고 싶을 것이다. 그러나 만약 분석하려는 인간이 자신이 자주 다니는 장소만으로 선택해서 이 지역이 유행하면 전국적으로 유행할 것이라는 가정을 통해서 한 지역만을 조사하거나 인터넷에 나오는 많은 패션 사진을 찾아 보지만 실제로 자신의 기호 혹은 선호도 preference 없이 객관적으로 사진을 모을 수 있을지 그리고 그 결과가 어떨지는 알 수 없다. 그러나 기계가 이런 작업을 수행하게 한다면 최근 패션에 관련된 사진들과 소셜 미디어에 올라오는 사람들의 일상 속에서의 패션들을 모아서 옷에서 나타나는 수치들 예를 들어 원피스의 경우 위와 아래가 구분되는 비율이나 옷의 형태뿐만 아니라 일상에서 어떤 옷을 입고 어떤 장소에 자주 간다와 같이 옷 뿐만 아니라 관련된 배경정보들까지도 포함해서 포괄적인 데이터를 분석할 수 있다. 뿐만 아니라 거의 실시간으로 데이터를 추가할 수 있기도 하고 인간이 궁금해 하는 부분들도 바로 분석할 수 있는 능력을 가진다. 기계가 인간보다 충분히 잘 할 수 있는 부분은 데이터가 많아진다면 그 데이터를 모아서 인간이 원하는 질문에 대답하기 위한 시간이 절약된다. 예를 들어 야외에 나갈 때 선호하는 패션은 무엇인지 물어본다면 인간은 다시 야외라는 조건을 포함해서 해당되는 데이터를 다시 보아야 하겠지만 기계에게는 그런 데이터를 처리하는 시간뿐만 아니라 결정적으로 인간이 제시할 수 있는 다소 모호한 그리고 광범위한 대답 예를 들어 "내년에는 무채색의 정장 스타일..." 과 같은 내용이 아니라 기계는 명도 채도 그리고 스커트의 길이는 어떤 비율과 같이 수치화 된 quantified 새로운 정보를 제시할 수 있을 것이다.
결국 기계가 인간보다 더 잘 할 수 있는 작업내용을 생각해보면 역시 데이터를 얻어내고 분석하고 이를 수치화 하는 작업을 우선 생각할 수 있다. 역시 좋은 목적으로 기계의 수집, 분석 능력을 사용할 수 있지만 개인이 인지하지 못하고 만들어 내는 수많은 데이터를 개인정보로 만들어 내는 작업도 분명 기계가 탁월하게 할 수 있을 것이다. 예를 들어 특정 인물이 어떤 곳에 살고 있고 가족 관계가 어떻게 되고 아이는 어떤 유치원에 다니는지 우리는 수작업으로 관음증 환자처럼 찾아내야 하는 작업들을 기계는 아주 쉽게 그리고 죄책감도 거의 가지지 않고 쉽게 할 수 있을 것이다.
Such a trivial data ...
대한민국은 주민등록 번호 하나로 수많은 개인정보를 얻어 낼 수 있는 무서운 국가 중 하나이다. 물론 국가가 국민을 쉽게 통제할 수 있는 수단으로 그리고 어떤 측면에서는 범죄자를 쉽게 찾아낼 수 있는 좋은 수단이라고 변호할 수 있지만 범죄자를 위해서 수많은 비범죄자의 개인정보까지 들춰질 권리까지 국가가 가져야 한다고 주장할 수 없다.
한국에서는 수많은 카페나 공공장소에서 인터넷을 쓸 수 있다. 예를 들어 카페에서 접속할 수 있는 소위 비밀번호 (정확한 의미에서 비밀번호는 아니다.) 를 입력하면 무선인터넷을 사용할 수 있다. 그러나 그와 함께 카페의 내부 인터넷에 들어갈 수 있다 혹은 공유기에 접속한다는 말이다. 그리고 공유기 관리를 위한 페이지에 접근할 수 있다. 공유기의 관리자 암호/패스워드가 기본값이라면 카페 관리자가 아니라도 쉽게 관리화면에 들어가서 수많은 설정을 바꿀 수 있다. 이론상 (그리고 현실상) 외부에서도 접근이 가능하다는 말이다. 그리고 공유기 설정값이 기본값으로 되어 있다면 수많은 공유기에 접근해서 원하는대로 설정을 바꿀 수 있다. 가장 쉽게 DNS 를 바꾸는 것을 생각할 수 있다. DNS 는 인터넷의 주소록이다. [ 인터넷의 주소록 DNS 서비스 ─ 기반기술에 대해서... ] 예를 들어 은행 업무를 위해서 yourbank.com 을 입력할 때 해당 도메인 이름이 어디에 있는 서버인지 알려주는 주소록이 DNS 인데 이 DNS 에서 yourbank.com 가 자신들이 만든 은행처럼 보이는 곳으로 알려주어 접근하게 한다. 잘못된 DNS 정보로 들어간 사용자는 자신은 은행업무를 본다고 생각하지만 가짜 은행 사이트에서 자신의 개인정보를 입력하게 된다.
실제로 내부 인터넷에 들어간다는 것은 외부에서 접근하는 것과는 차원이 다른 많은 부분들이 노출될 수 있다. 대표적으로 CCTV 도 들어가서 볼 수 있다. 인터넷을 제공하는 많은 곳에서 이처럼 자신의 공유기를 제대로 관리하지 않거나 CCTV 도 쉽게 기본값으로 들어갈 수 있는 곳을 자주 볼 수 있다. 종종 이런 이야기를 해주지만 대부분의 반응은 "별로 중요한 것도 없는데요." 혹은 "뭐 볼게 있겠어요." 라고 크게 무서워하지 않는 경우가 대부분 이었다. 그러나 대한민국이 아닌 다른 나라에서 이런 가능성에 대해서 이야기하면 상당 부분 놀라는 경우가 많았고 싱가포르와 같은 나라는 자신의 인터넷을 공개하거나 이렇게 위험에 노출시키면 안되도록 규제하고 있다. 권한이 없는 혹은 주인이 아닌 사람이 들어와서 영상 자료를 보는 것이 무엇이 문제일까 싶지만 개인적으로 생각한 창의적인(?) 생각은 노트북 쓰는 사람의 화면이나 키보드 입력 모습을 통해서 충분히 암호도 알아낼 수 있을 것이라고 생각했다. 실제로 공공장소에서 전혀 모르는 사람이 누구인지 그 사람의 소셜 미디어 계정을 찾아내는 방법은 다양하다. 책에 적어놓은 학번 / 이름 을 통해서도 알 수 있고 옆자리에 앉아 로그인하는 화면에서 이름이 누구인지 알 수도 있고 가끔 거울이나 물건 등에 반사되어 보이기도 한다. 지하철에 서서 가면 앞에 앉아 있는 사람이 무엇을 하고 있는지 시력이 좀 더 좋다면 그 사람의 계정 이름도 알아낼 수 있다.

유명한 사람도 아니고 내 개인정보가 뭐 중요하겠어 라고 생각할 수 있다. 대규모 서버에 공격하는 사람들도 많지만 의외로 전혀 들어올 이유가 없는 아주 사소한 서버에도 공격하는 사람들이 많다. 우리가 느끼지 못할 뿐이지 정말 정체를 알 수 없는 수많은 공격자들은 개인 서버인지 그냥 가정집 공유기인지 생각하지 않고 무조건 공격하는 경우를 자주 볼 수 있다. 개인적으로 관리하는 곳들은 모두 공유기에 접근하려다 실패하는 내용을 보지만 만약 공유기 관리 화면에 기본값으로 접근할 수 있다면 아마 공격자들이 의도한대로 접근해서 자신들이 원하는 작업을 했을 것이다.
How to protect privacy ...
무선랜을 사용하기 위해서 무선랜 비밀번호를 입력한다고 말하지만 정확히 이는 비밀번호는 아니다. 내가 접근하고 싶은 무선랜 이름 (SSID: service set identifier) 를 선택하면 네트워크 보안 키 를 입력하라고 나온다. 소위 '무선랜 비밀번호'는 키 key 이다. 간단하게 설명하면 우리가 입력하는 '비밀번호'는 무선랜을 써도 좋다는 허락을 위한 암호가 될 수도 있지만 사용자의 기기와 공유기가 데이터를 주고 받을 때 전달되는 데이터가 암호화가 될 수 있는 열쇠와 같은 것이다. 예를 들어 내가 데이터를 보낼 때 가장 먼저 공유기에 전달이 되어야 하는데 공유기에 전달되기 전에 내가 보내는 데이터를 '미리 정한(공유한) 키 Pre-Shared Key' 를 통해서 암호화를 해서 보내니 공유기 너는 이 키를 가지고 암호화한 데이터를 풀어서 받아 라고 규칙을 정한 것이다. 간단히 정리하면 사용자의 기기와 공유기 사이에 전달되는 데이터가 암호화하기 위한 것이다. 그래서 공개되어 '비밀번호가 없는' 무선랜은 그 사이에 전달되는 데이터가 암호화되지 않은 상태로 전달된다는 것이다.
데이터가 암호화되고 암호화되지 않은 것에 대해서는 조금은 민감할 필요가 있다. 옛날에는 안방에서 엄마가 전화하고 있으면 다른 방에서 수화기를 몰래 들어 통화를 감청(?)할 수 있었다. 마찬가지로 두 사람이 통화하는 중간 어딘가 똑같이 신호를 받아서 들을 수 있다면 같은 집 수화기를 통하지 않고도 들을 수 있다. 인터넷 데이터도 마찬가지이다. 암호화되지 않은 데이터는 어딘가에서 똑같이 받을 수 있다. 즉, 전달과정에서 동일한 데이터를 여러 곳에서 얻게 된다. 암호화가 되지 않았다면 내가 보내는 데이터 - 채팅 내용, 비밀번호, 주소록 등 - 모든 데이터 내용이 그대로 알아 볼 수 있는 형태로 얻게 된다. 그러나 만약 보내는 A 와 받는 B 둘만이 어떤 키를 가지고 있고 A 가 그 키를 통해서 보내는 데이터를 암호화해서 보내고 B 는 받은 데이터를 미리 공유된 키를 가지고 암호를 풀면 (복호화) 아무리 중간에 데이터를 얻게 된다고 해도 중간에서 데이터를 몰래 볼려고 한 사람은 암호화되어 알아낼 수 없는 데이터만 얻게 되는 것이다. 그래서 공개된 무선랜에 접속해서 인터넷을 쓴다는 것은 최소한 같은 공유기 내에 있는 사람에게는 암호화되지 않은 데이터를 누군가 몰래 볼 수 있다는 말이다.

인터넷에서 데이터 암호화는 상당히 중요하다. 그래서 이제는 거의 모든 웹서비스는 기본적으로 데이터 암호화 기술을 적용해서 사용하게 한다. 인터넷 주소창에 http:// 로 시작하는 주소와 https:// 로 시작하는 주소를 볼 수 있다. http:// 는 공개된 무선랜이라 생각하면 된다. https:// 는 사용자와 서버 사이의 데이터를 암호화해서 전달한다고 생각하면 된다. 다시 말해 http:// 를 보고 입력하는 정보들은 전달되는 과정에서 암호화되지 않은 상태 그대로 누군가에 의해 노출될 수 있다. 반면 암호화가 되어 있는 서버 사이에서는 내가 입력한 정보들은 암호화가 되어서 중간에서 데이터를 가져가도 암호화된 데이터만 가져가 제대로 된 키가 없다면 제대로 된 정보를 얻어낼 수 없다. 그래서 암호화된 주소 https:// 를 가지는 웹서비스만 사용하도록 습관을 가지는 것이 좋다. 조금만 관심을 가지고 보면 알겠지만 대부분 주요 서비스들은 암호화는 기본이고 데이터 암호화 통신의 중요성을 인식하고 있는 단체를 중심으로 개인들도 암호화를 쉽게 그리고 비용없이 적용할 수 있도록 도와주고 있다. 가장 대표적인 곳이 Let's Encrypt 이고 개인도 간단한 설정만으로 적용할 수 있다. 그리고 많은 기업들은 데이터 암호화가 기본이 될 수 있도록 필요한 비용과 지원을 하고 있다. 그만큼 우리가 일상적으로 사용하는 데이터가 누군가에 의해서 탈취당해서 악의적으로 사용될 가능성, 아무리 '사소한' 개인의 데이터라고 해도 보호되어야 한다는 철학을 가지고 있는 것이다.
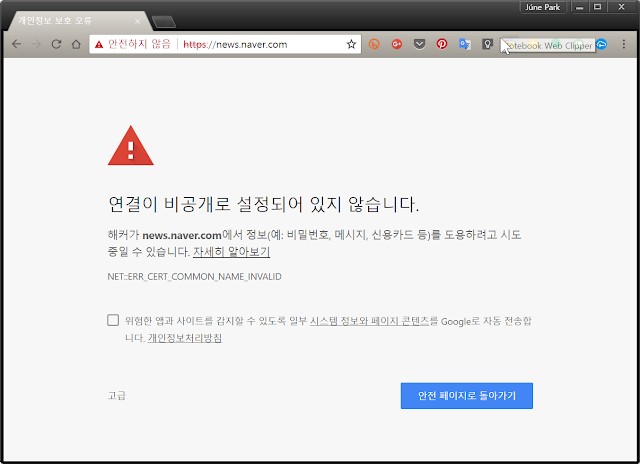
데이터 암호화가 적용되었는지 아닌지 살펴보면서 인터넷을 돌아다니다 보면 대한민국의 주요 기업들은 여전히 부족하다는 것을 알게 된다. 심지어 인터넷이 사업의 중심인 회사들조차도 자신의 서비스를 제대로 된 암호화를 제공하지 않고 서비스하는 것을 볼 수 있다. 알 수 없는 회사의 심오한 경영 철학이 있다면 할 수 없지만 개인 데이터의 중요성을 누구보다 잘 알고 있고 그런 사용자의 데이터가 어떤 기업보다 기업 경영의 자산인 기업에서 이렇게 보호되지 않는 웹서비스를 한다는 것은 조금 이해하기 어렵다. 뭔가 이해할 수 없는 심오한 그리고 기술적 진보로 암호화되지 않은 인터넷 환경에서도 개인의 데이터를 보호할 수 있는 최첨단 기술이 존재할 것 같지도 않다.
Less better than more ...
보안에서 한가지 원칙은 자신의 민감한 정보들은 자주 입력하지 않는 것이다. 예를 들어 브라우저에 비밀번호를 저장하고 들어갈 때마다 브라우저에서 비밀번호를 넣어주는 것과 들어갈 때마다 사용자가 비밀번호를 입력하는 것 중에서 어떤 것이 더 안전한지 묻는다면 대부분 브라우저에 자신의 비밀번호가 저장되어 있다는 사실때문에 매번 비밀번호를 입력하는 것이 더 안전할 것이라고 생각할 수 있다. 그러나 사용자가 키보드나 터치스크린을 통해서 입력하는 과정에서 발생할 수 있는 시각적인 해킹 - 사용자가 키보드를 입력하는 움직임을 통해서 비밀번호를 알아내는 - 이나 키보드 로그 - 키보드의 기록값을 몰래 저장하는 - 를 통해서 유출될 가능성이 있다. 그러나 브라우저에 저장된 비밀번호를 바로 암호 입력부분에 넣게 된다면 최소한 키보드 입력에 의한 위험성은 줄일 수 있다. 그러나 여기에서 더 중요한 부분이 있다. 사용자가 기억할 정도의 비밀번호는 두가지 위험성을 동시에 가지고 있을 가능성이 높다. 첫번째는 자주 쓰는 비밀번호가 한두개 정도 심지어 아예 동일한 비밀번호를 사용하고 있다면 다른 웹서비스에서 유출된 비밀번호가 바로 다른 웹서비스에서 사용될 수 있게 된다. 그리고 사용자가 입력을 매번 할 수 있다는 것은 사용자가 기억하고 있다는 것이다. 사용자가 기억할 수 있는 memorable 비밀번호란 어느정도 유추할 수 있는 비밀번호일 가능성이 높다.

그래서 비밀번호는 아예 사용자가 모르는 것이 가장 안전할 수 있다. 문제는 자신의 비밀번호인데 자신이 모르고 기억하지 못한다는 것이 말이 안되는 소리같다. 브라우저가 비밀번호를 저장하고 있듯이 비밀번호만 대신 저장해서 관리해주는 프로그램도 가능하다. 접속하는 웹서비스에 맞는 사용자 이름 / 비밀번호를 저장하고 있다가 필요한 항목에 사용자 이름 / 비밀번호를 대신 입력해주는 것이다. 사용자가 입력할 필요가 없다. 만약 각 웹서비스 별로 비밀번호를 저장할 수 있다면 비밀번호를 기억할 필요도 없고 얼마든지 길게 그리고 복잡하게 비밀번호를 입력해도 괜찮다. 다만 비밀번호를 관리하는 프로그램을 실행시키기 위한 비밀번호는 기억하고 입력해야 할 것이다. 모든 웹서비스의 비밀번호가 모두 다르다면 한 웹서비스에서 유출된 자신의 비밀번호를 걱정할 필요가 없을 것이다. 유출된 비밀번호를 통해 다른 웹서비스에 들어갈 수 없기 때문이다. 좀 더 보안에 신경쓰기 위해서는 2차 인증 2-step verification 을 사용하는 것이다. [ 인터넷 보안 - 나의 계정을 지키자 ]
공용 컴퓨터를 자주 사용하기 보다는 정해진 기기에서만 접속할 수 있다면 좋을 것이다. 자주 개인정보가 입력될 수록 분명 노출될 가능성은 높아지기 때문이다. 공용 컴퓨터는 특히 어떤 악의적인 프로그램이 설치되어 있을지 데이터 전달을 위한 안전한 환경인지 확인할 수 없기 때문이다. 인증을 위한 다양한 방법을 제시하는 것도 좋다. 로그인을 하면 2차인증을 통해서 다시 한번 확인할 수 있지만 등록된 스마트폰에 간단한 메세지를 보내 로그인을 위해 확인하는 방법도 있고 확인 메일을 보내서 메일에 포함된 확인 주소를 통해서 인증해서 들어갈 수 있다. 모든 방법들은 사용자의 편의를 위한 부분도 있지만 만약 비밀번호가 유출되었다고 해도 본인을 인증할 수 있는 다양한 방법으로 본인이 아닌 다른 사람의 접근을 막기 위해서이다. 사실 2차인증도 완벽하게 안전하다고 말할 수 없다. 가장 창조적인 방법으로 이미 유출된 개인 아이디와 비밀번호를 통해서 접근을 하고 SMS 로 2차인증 번호를 보내주는 계정의 통신사 SMS 서버를 해킹해서 중간에 2차인증 번호를 받아서 이를 입력해서 들어간 경우도 있었다. 더 강화된 다양한 기술을 적용하지만 최소한 진짜 사용자가 접근하는 모든 방법을 그대로 수행한다면 들어가는 것을 막을 수는 없을 것이다.
그렇다면 이렇게 애쓰며 남의 계정을 들어가려고 하는 것일까? 그 속사정을 알수는 없지만 무엇인가 이득이 있기 때문에 그렇게 애쓴다고 할 수 있을 것이다. 가장 쉽게 볼 수 있는 경우는 광고용으로 사용하기 위해서 타인의 계정에 들어가는 것이다. 이미 만들어진 계정이고 자신의 신분을 효과적으로 숨길 수 있고 유출된 비밀번호라면 특별히 계정을 만드는 것보다 더 안전하기도 하기 때문이다. 그리고 자신의 계정으로는 쉽게 올리기 힘든 강도높은(?) 광고들도 올리고 계정이 삭제되더라도 괜찮기 때문이다. 그리고 여러개의 계정을 가진다는 것은 그만큼 접속 회수를 늘릴 수 있는 도구로 사용될 수 있다는 것이다. 이해할 수 없지만 좋아요 ♥ 가 많이 달린 개시물에 대해서는 알 수 없는 신뢰를 보인다. 다수가 좋아하는데 무슨 문제있겠어 혹은 다수가 인정하니깐... 과 같은 요소는 우리가 냉정하게 판단하기 보다는 처음부터 편향된 방향으로 생각하기 쉽도록 만들거나 특별히 큰 관심을 가지지 않는 부분도 거의 유일하게 신뢰할 수 있는 것은 다수의 긍정이라는 사실이라고 믿기 때문에 타인의 수많은 계정을 동원해서 좋아요 숫자만 올리는 것으로 광고효과가 좋다고 믿는 이들에게는 다수의 계정을 확보하는 것이 중요할 것이다.
Data is flowy ... Information is ...
우리가 인식하지 못한 상태에서 수많은 데이터를 만들어 내고 있고 그 데이터는 우리의 의도와는 다르게 사용되기도 한다. 그 모든 순간에도 생각해 볼 부분은 바로 데이터는 흐름이라는 점이다. 숫자 혹은 단순한 문자에 불과하다고 생각할 수 있지만 데이터는 흐름이 존재할 때 더 많은 가치를 가질 수 있는 가능성을 가지게 된다. 그래서 많이 사용되는 데이터일 수록 정보에 더 많은 영향을 줄 수 있는 가능성이 높고 그만큼 중요한 데이터가 될 수 있다. 그래서 데이터는 가치판단 뿐만 아니라 옳고 그른 판단을 내릴 수 없다. 숫자 3.141595 가 나쁘다라고 말할 수 없기도 하지만 심지어 '살인'이라고 해도 '가족을 지켜내기 위해서 강도를 살인하다' 라고 한다면 살인 하나만으로 나쁘다고 말할 수 없기 때문이다.
그만큼 데이터란 우리에게 알려주는 정보의 단편 혹은 아직 분석되지 않은 사실의 흐름일 뿐이지 그 데이터가 우리에게 좋다 나쁘다를 말해줄 수 없다. 문제는 데이터를 어떻게 관리하고 어떻게 통제하는가의 문제이다. 유리한 데이터만 보여주고 불리한 데이터는 감춘다고 해도 데이터는 흐름을 가지기 때문에 데이터의 흐름이 끊어진다면 우리는 그 데이터를 신뢰할 수 없게 된다. 큰 범위에서 의도적으로 조작된 데이터는 항상 스스로 잘못된 부분을 알려주기 마련이다. 일부러 감추려는 데이터는 그 흐름이 인위적으로 끊길 수 밖에 없기 때문이다. 이러한 데이터의 특징을 잘 모르고 감추기 위해서 데이터를 조작하거나 숨기는 것은 자신에게 유리한 / 불리한 데이터가 존재한다고 가치판단을 하기 때문이다. 조작된 데이터를 보여줄려고 한다면 차라리 아무것도 공개하지 않는 것이 숨기려는 자들에게는 최선의 선택이라는 것 아니면 모든 것을 그대로 밝히는 것이 가장 좋을 것이다.

그래서 데이터란 숨기고 보여주지 않으려고 하고 데이터의 관리를 통제하려고 하는 것보다 투명하게 공개하는 것이 중요하다. 그런 의미에서 있는 그대로의 데이터와 그 데이터의 흐름을 숨기지 않으려는 것을 투명성 transparency 라고 한다. 2000년대 말 사용자의 개인정보를 관리하는 기업 특히 구글을 중심으로 해서 데이터의 투명성이 중요하다고 강조했다. 구글 투명성 보고서 페이지에 소개된 투명성에 대한 간단한 설명은 다음과 같다.
결과적으로 공유 (제공) 하는 것은 데이터이다. 그 데이터의 성격은 정부 및 기업의 정책과 조치가 개인정보, 보안, 정보 이용에 미치는 영향을 보여준다. 간단하게 설명하면 정부가 요구해서 어떤 범죄 의심자의 위치, 지역이나 관심 분야 등과 같은 개인정보를 얼마나 제공했는지 그리고 그 이유는 무엇이였는지 알려주는 것이다. 그리고 어떤 이유에서 개인이 올린 데이터를 삭제했는지 서비스 장애에 의해서 개인이 제대로 데이터를 관리할 수 없는 순간은 없었는지 보고하는 것이다. 다양한 내용들이지만 서비스 전반에 걸친 모든 데이터의 흐름이 어떻게 진행되고 있는지 데이터의 흐름에 영향을 줄 수 있는 모든 상황 / 조건을 공개한다는 것이다. 중요한 점은 데이터의 흐름을 막거나 통제하는 것이 아니라 가급적 데이터가 잘 흐를 수 있도록 하고 그 과정에서 그 흐름을 막거나 바꿔야 하는 경우가 있었다면 그 이유와 결과를 보고하는 것이다. 따라서 투명성이란 개인정보가 어떻게 어디로 흘러갈 수 있는지 확인할 수 있는 중요한 부분이다.
NGO 단체인 국가투명성기구 (Transparency International) 는 국가의 청렴도 반대로 부패지수를 발표한다. 부정부패는 사회나 국가에서 인간을 억압하고 고통을 주는 요소라고 생각한다. 정직하게 생각하고 이를 행동하려고 해도 부정부패가 만연해 있다면 제대로 자신의 양심대로 살아가기 어려울 뿐만 아니라 대부분 희생자가 될 것이라는 점이다. 그리고 부정부패의 가장 큰 적은 부정부패의 상황을 제대로 밝히지 않고 숨기기 때문이라고 보았다. 그래서 국가의 투명성은 부정부패의 정도를 알려서 얼마나 많은 비정상이 존재하는지 알리는 것이라고 본다. 웹서비스도 비슷하다. 좋은 웹서비스가 존재하고 사용자들이 잘 사용해 유용하다고 해도 자주 서비스가 중단되거나 소수의 이익만을 위해서 운영되면 안되기 때문이다. 어떤 문제도 발생하지 않는다면 좋겠지만 완벽할 수 없다면 문제가 되는 부분을 공개하는 것이다. 그리고 문제가 되는 부분을 투명하게 사용자들이 알게 된다면 자신이 사용중에 발생한 문제가 자신의 문제인지 서비스의 문제인지 파악할수도 있을 것이다. 투명성이란 모든 이들이 사용하는 서비스 그리고 그 과정에서 발생하는 모든 데이터에 대한 흐름을 파악할 수 있도록 해줘야 한다는 생각이다.
GDPR ...
요즘은 메일함에서 GDPR 에 대한 메일을 쉽게 본다. GDPR 는 General Data Protection Regulation 의 약자로 유럽연합이 유럽전역을 우선 대상으로 적용하는 '일반 개인정보보호 규정'이라 부른다. 그러나 General 을 그대로 해석해 일반이라고 표현하지만 적극적으로 일반이 아닌 '모든' 혹은 '통상' 이라고 부르는 것이 더 정확할 것 같다. 다시 말해 특별한 조건이 붙지 않는다면... 데이터의 관리, 처리에서 발생하는 문제는 누구의 책임인지 그리고 그 역할에 대해서 정의내리고 있다. 물론 유럽연합에 적용되는 규정이기 때문에 타 지역에서 지키지 않아도 되겠지 싶지만 데이터는 흐름이고 그 흐름에는 특별히 국경의 의미가 존재하지 않는다는 점 그리고 전략적으로도 유럽은 상당수의 데이터의 관리 주체라는 점에서 실질적으로 유럽연합의 적용은 전세계의 적용이나 다름없다. 뿐만 아니라 이 규정에서는 우선적으로 '확장된 영토 적용 범위'를 통해서 지리적 구분이 중요한 것이 아니라 데이터의 흐름이 중요하다고 강조하고 있다.

GDPR 에서 제시하는 중요한 개념에는 Controller 와 Processor 가 있다. Controller 는 '정보통제자' 혹은 '정보관리자' 라고 해석하기도 하고 Processor 는 '정보처리자' 혹은 '정보가공자' 라고 해석하기도 한다. 그냥 컨트롤러 / 프로세서 라고 그대로 쓰기도 한다. 한국어 번역의 기본 내용이 없어 그대로 컨트롤러 / 프로세서로 표현한다. 컨트롤러란 개인정보를 포함하여 개인이 만들어내는 데이터의 수집, 관리 그리고 광범위한 범위에서의 삭제까지 포함하는 데이터 / 개인정보를 어떤 방식으로 관리해야 하는지 책임의 범위를 확대했다. 개인 계정의 해킹에 의해서 노출된 개인정보라면 그 책임이 누구에게 있는지 범위를 확대하고 컨트롤러가 다양한 수단을 사용하려고 노력했지만 어쩔 수 없음을 증명하지 못한다면 컨트롤러의 책임이 있다는 점을 강조했다. 프로세서는 개인정보를 분석, 가공하는 과정에서 필요한 원칙과 역할을 제시했다. 그리고 무엇보다 어떤 과정에서 개인정보 유출되었을 때 적절한 통지를 해야한다. 예전에는 투명성을 통해서 데이터의 흐름을 파악할 수 있도록 했다면 GDPR 이후에는 개인정보가 유출되거나 남용되는 순간에 개인이 바로 알 수 있도록 알려야 한다. 그래서 개인정보의 주체는 권리가 확대되어 개인이 필요하다면 자신의 개인정보의 보관 삭제에 대한 적극적인 권리를 행사할 수 있도록 보장한다. 즉, 개인정보를 지우고 싶다면 개인정보를 보관, 관리, 가공하는 주체들이 이를 실행하고 이 결과를 개인에게도 알려야 한다.

이 정도 내용이라면 개인의 권리는 증가하고 기업은 불리해지는 것은 아닐까 생각하지만 중요한 점은 개인이라도 충분히 컨트롤러나 프로세서가 될 수 있다는 점을 생각해야 한다. 만약 내가 인터넷에서 우연히 얻은 개인정보를 통해서 분석을 한다고 해도 그 개인정보의 주체가 요구한다면 아무리 상업적 목적이 아니라도 그 요구를 들어주어야 한다. 심지어 개인 서버를 운영하고 있고 개인이 접속해서 남긴 다양한 개인정보 - IP 주소, 지역 등 - 에 대해서 수집하는 순간 개인도 컨트롤러가 바로 된다. 결국 기업 / 개인을 위한 규정이 아니라 어떠한 데이터를 얻고 처리하고 살아가야 한다면 이 규정에 적용받지 않을 수 없다는 것도 인식해야 한다. 결국 개인정보에 대한 중요성을 강조하게 되면서 수많은 데이터의 흐름에 대해서 민감하게 인식해야 하는 세상이 되었다.
Cannot be too sensitive ...
전세계의 거의 모든 데이터를 감시하고 테러와 같은 위험을 알아내서 미리 막을 수 있다면 자신의 개인정보도 기꺼이 제공할 수 있는지 묻는다면 어떻게 대답할 것인가? 역설적으로 데이터를 통해서 테러를 막을 수 있다는 생각은 실제로 데이터가 얼마나 중요한 것인지 심지어 현실에서의 행동까지도 미리 막을 수 있다는 뜻이고 이는 데이터 그리고 개인정보는 우리가 생각하는 것보다 높은 생명력(?)을 가지고 있다는 뜻이다. 개인정보는 우리의 삶과 연결되기도 하고 나쁜 목적이라면 한사람의 삶까지도 좌우할 수 있는 무서운 정보이다.
실제로 온라인에서만 이야기를 나누던 상대방에게 화가 나서 마음 먹고 상대방의 실제 거주지와 동선을 파악해서 살인을 했다는 이야기부터 앞서 이야기한 것처럼 가족관계나 사람들에게 협박이 될 수 있는 다양한 정보들을 통해서 두려움에 떨게 만들 수 있기 때문에 개인정보는 충분히 생명력을 가지고 있다. 그리고 생명력이란 타인에게 위협이 될수도 있고 실체하는 physical 위험이 될 수 있기 때문에 스타워즈 1편의 제목인 '보이지 않는 위험 The Phantom Menace' 이 될 수 있다. 현실에서도 인간을 가장 두렵게 만드는 것은 당장 눈앞에 있는 공포나 위험일 수 있지만 단순한 정보 그리고 그 정보에서 나오는 가능성이 큰 공포와 두려움을 만든다. 그리고 인간은 그 공포와 두려움을 피하기 위해서 비논리적인 행동도 하게 된다.

그래서 우리의 개인정보들에 대해서 아무리 민감하게 생각해도 지나치지 않는다. 물론 지나친 생각으로 그 자체가 두려움이 되어 공포 안에서 살아가라는 뜻이 아니라 잘 대처하기 위해서 데이터의 본질과 흐름을 파악하고 개인정보가 어떻게 만들어지고 어떻게 노출될 수 있는지 상식처럼 알아 놓는다면 자신도 모르는 본인의 개인정보로 피해를 보기 전에 대처할 가능성이 높아질 것이다.
Who owns privacy ...?
개인정보는 누구의 것인가? 개인이 보관하고 관리하는 개인의 것이지만 프로세서 Processor - 정보가공자가 만들거나 찾아낸 혹은 분석해서 밝혀진 개인정보라면 그 정보는 누구인지 설명하기 어려울 때가 있다. 예를 들어 자신이 올린 위치 정보가 없는 사진들을 통해서 누군가 사진의 배경이나 주변 정보를 통해서 '누가 사는 곳은 어디이다' 라는 개인정보를 알아냈다면 해당 개인정보는 누구의 것인지 생각해야 한다. 즉, 데이터가 수없이 만들어지고 데이터가 가공되는 과정에서 해당되는 개인들도 인식하지 못하는 정보들은 누구의 것이며 만약 분석한 주체와 상관없이 해당 개인정보 당사자의 것이라고 한다면 당사자는 어떻게 자신도 모르지만 만들어진 개인정보가 있는지 그리고 삭제하고 싶다면 어떻게 할 수 있는지 쉽지 않은 문제이다.
그래서 소위 '잊혀질 권리'를 이야기하지만 정작 잊혀질 권리를 주장할 수 있는 개인정보가 어디에 어떻게 저장되어 있는지 본인도 제대로 확인할 수 없고 검색되지 않는 개인정보는 처리할 수 있는 방법이 없다. 그렇기 때문에 개인정보를 관리하고 가공하는 주체를 나누고 각자의 역할과 책임을 설명하고 있는 유럽연합의 GDPR - 일반 개인정보보호규정 은 지키지 못하거나 책임을 다하지 못한 상황에서 과징금이나 개인 피해에 대한 보상 규정도 포함한다. 그러나 실질적인 문제는 자신이 관리하지도 않는 개인정보를 어디에 있는지 알기 어렵다. 예를 들어 환자의 임상 데이터를 모아서 의학 발전에 도움이 되도록 모을 때 환자가 누구인지 알 수 있는 내용을 제거해서 개인정보였던 내용이 임상 데이터가 된다. 즉, 개인정보에서 개인이 누구인지 알 수 없게 하지만 임상에는 도움이 될 수 있는 데이터로 만드는 것이다. 문제는 제대로 제거했는지 확인하지 못한 상태에서 다른 기관에 임상 데이터를 넘기는데 개인정보가 제거되지 않은 상태로 넘어갔을 때 우리에게 넘어온 임상 데이터가 '당신의 개인정보가 포함되었다' 라고 당사자에게 알려준다면 환자의 의료 정보를 수집한 기관에서 제대로 데이터의 관리를 하지 않았다는 것을 동시에 알리게 된다.

데이터는 흐름이기 때문에 그 흐름에서 누구의 책임인지 찾는 것은 의외로 쉬울 수 있지만 그때 누가 어떤 책임을 가지며 어떤 처벌을 받을 수 있는지는 신중하게 생각해야 한다. 개인정보가 포함된 임상 데이터를 받았을 때 신고하면 신고한 기관은 책임을 면할 수 있다고 해도 그 데이터를 전달해준 기관은 자동으로 책임을 지게 되기 때문이다. 그래서 이런 실수를 제거하기 위해서라도 데이터와 개인정보를 구별하고 정의할 수 있는 방법이 필요하다. 앞서 설명한 것처럼 데이터를 통해서 개인정보를 찾아내는 일을 인간보다 기계가 잘 할 수 있다면 반대로 받은 임상 데이터에서 개인정보가 포함되어 있는지 확인하는 방법도 인간보다 기계가 더 잘 할 수 있을 것이다. 기계에게 임상 데이터를 받게 되었을 때 알 수 없는 환자가 누구인지 알아낼 수 있다면 알아낼 때 단서가 되는 데이터를 제거해서 개인정보가 사라진 임상 데이터로 만들면 되기 때문이다.
역설적으로 데이터에서 알아낼 수 있는 수많은 개인정보들도 기계가 잘할 수 있지만 동시에 개인정보를 찾아낼 수 있는 심지어 그 단서까지도 포함해서 개인정보를 잘 처리할 수 있는 역할을 기계가 잘할 수 있다는 점이다. 이를 응용한다면 사람이 검색과 수작업을 통해서 찾아내고 판단해야 하는 개인정보를 기계가 스스로 학습해서 개인정보를 효과적으로 제거할 수 있다. 가장 대표적인 예는 지도 서비스에서 나오는 수많은 차들이나 사람들의 얼굴 그리고 개인정보로 노출 될 수 있는 많은 개인정보들을 자동으로 흐리게 만들어서 알 수 없도록 하는 것이다. 앞서 예를 들었던 환자의 의료 정보들도 의학적 의미를 살릴 수 있는 수준까지 임상 데이터를 살리고 그 외에 불필요한 정보가 무엇인지 인간보다 더 잘 판단해서 제거할 수 있게 된다.
Human, citizen, ... Identity ...
인간에 관한 권리에 대해서 하나의 문장으로 정리하기 시작한지 그렇게 오래되지 않았다. 정말 반세기 전에는 흑인, 백인이 분명히 구별되어 차별받았던 시절이였고 여성의 참정권이 보장된 것도 그리 오래되지 않았다. 자신이 선택할 수 없는 내용으로 차별을 받지 않아야 한다는 소극적인 형태의 차별금지를 떠나서 자신의 신념, 생각과 같이 스스로 선택했던 것이 인류에 해를 줄 목적이 아니라면 그 어떠한 생각조차도 차별의 대상이 될 수 없다고 해도 여전히 차별과 협오의 시대를 살고 있다. 그러나 조금씩 그 의미에 대해서 고민하고 공론화되면서 다양한 분야에서 그런 차별의 요소를 줄이고자 하는 노력들은 분명 인류의 진보라고 믿게 된다.
예전에는 상상하기 힘들었던 동성애의 사랑을 이제는 드라마에서 쉽게 볼 수 있고 (대한민국은 여전히 아니지만...) 그런 삶의 모습도 우리의 주변에서 일어나는 일들이라고 긍정적으로 받아들일 수 있게 되었다. 그래서 현대 사회에서의 인권이란 우리의 상상력이 어떻게 작용하냐에 따라서 그 범위가 달라질 수 있다. 사회의 변화 이제는 기술의 변화로 인간의 삶이 달라지고 그 결과 얻어지는 모습들이 달라지기 때문에 그런 변화에서 만들어지는 다양한 인권의 범위도 확대해야 하는 것이 사실이다. 그러나 종종 기술이 만든 다양한 모습에 법이 따라가지 못하는 경우를 보면 법이나 규제가 가져야 하는 유연성에 대해서 적극적으로 고민해야 할 시점이라고 본다.

인간에 대한 인권만으로 설명하기 힘들어서 국가 사회에서 시민으로 가지는 권리로 시민권을 생각하게 되었듯 기술의 발달로 만들어지는 개인정보와 데이터에 대한 고민을 통해서 인간이 데이터없이 살아갈 수 없는 그리고 그 데이터로 피해를 보고 때로는 이득을 보는 현실 세상에서 개인정보에 대한 범위까지 포함할 수 있는 정체성을 가지는 자아로 설명될 수 있는 어떤 권리 장전이 필요한 시점이라고 느낀다. 많은 경우 진보적인 생각을 가진 이들과 그런 생각이 필요없는 기득권 사이에서의 계급투쟁으로 얻어지고 그 과정에서 많은 희생이 필요했던 것도 사실이지만 분명 필요한 것은 변화하는 모습에 대해서 어떤 모습의 인간이 더 행복할 수 있는 가능성이 높은지 고민하는 과정일 것이다.
그 과정 속에서 기계 혹은 인공지능으로 대변되는 기계 기술이 영화 터미네이터 (1984) 에서 그려지듯 인간을 억압하는 존재가 아니라 인간의 권리와 확대되는 정체성을 보호할 수 있는 장치로 작용할 수 있기를 바란다. 그리고 그런 작업에서 인간보다 기계가 넓은 범위에서 더 잘 할 수 있다면 기계학습을 통해서 개인정보를 어떻게 보호할 수 있을지 고민하는 것도 필요하다고 본다. 그리고 어쩔 수 없이 수많은 데이터 속에서 작업해야 하는 인간에게 그런 개인정보를 보호할 수 있는 도구로 인공지능이 활용된다면 인간의 직업을 빼앗는 인공지능이 아니라 인간이 특별히 고민하지 않고 좀 더 창의적인 내용에 더 투자할 수 있도록 잡일들을 처리해줄 수 있는 조력자로 인공지능이 존재하고 인간의 직업을 차지하는 역할이 아닌 인간의 작업내용을 더 효율적으로 처리할 수 있도록 도와주는 존재가 될 것이라고 본다.
그렇게 인공지능이 인간에게 도움이 될 수 있는 존재가 될 수 있기를 바란다면 우선 데이터와 개인정보로 넘쳐나는 현실에서 신경쓰이는 수많은 데이터 처리와 개인정보 보호의 역할을 충실하게 수행할 수 있는지 그렇게 도와줄 수 있는 기술의 형태는 어떻게 되어야 하는지 생각해야 할 것이다.

습관적으로 매일 아침, 저녁으로 먹어야 하는 사람에게 약을 먹으라고 알람을 울리는 것도 좋은 방법이다. 지금 하고 있는 일이 있어서 나중에 먹어야 겠다 마음먹고는 잊어버리는 경우도 있고 방금 전에 먹었는지 아닌지도 확실하지 않을 때도 있다. 요일별로 나누어진 약 상자라면 오늘 요일을 확인하면 되지만 만약 요일별로 있지 않을 때도 방법이 있다. 약 상자에 약을 넣을 때 7의 배수로 넣는 것이다. 7개, 14개 약이 작다면 21개 이런 식으로 넣는다. 저녁 약을 잘 먹어오다가 목요일 저녁에 약을 먹었는지 아닌지 모르겠다면 남아 있는 약을 세어 보고 만약 3개, 10개가 남았다면 먹은 것이고 4개, 11개가 남았다면 목요일 저녁에 약을 아직 먹지 않은 것이다.
알약의 개수는 데이터이다. 몇개가 남았는지는 우리에게는 그냥 주어지는 데이터일 뿐이지만 요일 정보와 결합이 될 때 우리가 무엇을 했는지 아닌지를 알 수 있는 개인에게 관련된 정보가 되는 것이다. 데이터는 단순한 숫자 혹은 문자열일 수 있지만 데이터가 개인의 상황 혹은 조건과 결합이 되면 개인에게 의미가 있는 정보가 될 수 있다. 알약의 예에서 3개, 10개가 남은 것은 단순한 데이터이지만 이것이 목요일이라는 정보 그리고 매일 약을 먹는 사람이라는 상황이 결합이 되면 개인이 약을 저녁에 먹었는지 아닌지 알 수 있게 된다. 데이터란 무엇이며 데이터가 가지는 힘, 그리고 그 힘이 우리에게 어떻게 다시 영향을 줄 수 있는지를 이해하는 것은 정보의 바다에서 최소한 익사하지 않기 위한 구명정이라 생각하게 된다.
Datum Era ...
데이터는 번역하면 단순하게 자료로 번역되지만 단순히 조금 부족한 느낌이 들기 때문에 외래어로 데이터로 사용할 것이다. 데이터의 어원은 라틴어 datum 그리고 datum 은 '주다'는 뜻의 dare 에서 유래되었다. 무엇인가를 설명하기 위한 기초적인 자료 누군가를 설득시키기 위해 필요한 모든 자료들을 데이터라고 말하고 수리적으로 계산하기 위한 대상이기도 하다. 예를 들어 건물의 높이를 측정하기 위해서 높이가 몇 m 이고 넓이는 어느정도라고 말하는 대부분의 숫자들은 우리가 건물의 규모를 이해하기 위해 필요한 숫자들이다. 그리고 그 숫자를 통해서 건물의 가치가 어떻게 된다와 같은 논리적인 내용을 이어가기 위한 내용들이다. 쉽게 이해할 수 있지만 실제로 데이터는 숫자 그리고 간단하게 교환될 수 있는 문자 정도로 구성되어 있다. 대부분이 숫자이고 컴퓨터의 발달로 문서 내용이나 사진, 음원 등과 같은 거의 모든 내용들은 0, 1 로 이루어진 숫자로 표현이 가능하게 되었다.
간단하게 모든 데이터는 숫자로 표현할 수 있게 되었다고 설명할 수 있지만 중요한 것은 이렇게 표현된 숫자들이 우리의 삶에서 중요한 의사결정을 하는데 무엇을 평가하거나 계획하는데 필요한 숫자들이라는 점이다. 조금 과장해서 이 세상이 0, 1 로 이루어졌다고 할 수 없지만 0, 1에 의해 세상이 움직일 수 있다고는 말할 수 있을 것이다. 영화 매트릭스 (1999) 는 우리가 살고 있는 세상도 실제로 존재하는 곳이 아닌 데이터로 이루어진 곳이며 우리는 그것을 인식하지 못하고 살아갈지 모른다고 이야기해주었다. 소위 빨간약 / 파란약의 선택에서 파란약을 먹는다면 예전처럼 살던 모습대로 살아가고 빨간약을 먹게 된다면 매트릭스 그리고 데이터가 만들어 놓은 실제 세상에서 싸우게 되는 것이다. 파란약을 먹고 망각과 평온의 세상을 살게 될지 빨간약을 먹고 자각과 고통의 세상을 살 것인지 선택하게 된다. 매트릭스처럼 모든 것이 데이터로 이루어진 세상에 허구로 살아가는 존재는 아니지만 우리가 무의식 속에서 흘러가는 수많은 데이터들을 인식하게 되는 순간 세상은 우리가 생각하는 것만큼 데이터의 주인은 우리가 아니라는 사실을 알게 될 것이다. 그래서 영화 매트릭스가 우리에게 전해주고 싶은 이야기는 허구 / 실체의 구별이 아니라 우리가 얼마나 많은 데이터를 만들어 내고 개인정보들이 흘러 나오지만 우리는 그 데이터의 흐름을 인식하지 못하고 있는지 알려주고 싶었는지 모른다.
 |
| 매트릭스 (1999) |
다시 정리하자면 데이터는 의미없는 숫자나 정보까지도 모두 다 포함한다. 그러나 데이터가 조건 condition 과 상황 circumstance 과 결합이 되면 개인정보가 될 수 있다. 앞서 설명한 것처럼 약의 개수는 단순한 데이터지만 약을 매일 먹는다는 조건과 약을 7의 배수로 상자에 넣은 상황이 결합되면 오늘 약을 먹었는지 아닌지 알 수 있게 된다. 우리가 민감하게 생각하는 개인정보 privacy 란 데이터와 조건, 상황이 포함된 결과물이다. 모든 데이터가 개인정보는 아니지만 모든 개인정보는 데이터라고 말할 수 있다. 개인정보의 저장, 전달 및 가공의 단계를 고려해서 우리가 만든 데이터들이 얼마나 많은 개인정보로 전달 가공될 수 있는지 생각해 볼 필요가 있다.
Data Tsunami ...
개인은 얼마나 많은 데이터를 만들고 있고 내가 만든 데이터는 모두 나의 개인정보가 되는지 그리고 내가 만들지 않은 데이터가 나의 개인정보가 될 수 있는가 고민하지 않는다. 특별히 내가 만드는 데이터가 많지 않을 것이라는 생각과 함께 내가 만든 데이터가 중요하지 않을 것이라고 생각하기 때문이기도 하다. 그러나 결론부터 말하면 데이터의 가치는 중요하지 않다. 다시 강조하지만 데이터가 어떻게 개인정보를 포함해서 어떻게 중요한 정보가 될 수 있는지는 조건과 상황에 따라서 달라진다. 냉전시대 인터넷이 중요하지 않은 시절에는 인터넷을 연결할 수 있는 정보 그리고 관련된 데이터는 분명 중요하다 못해 극비 데이터였지만 이제는 누가 가지라고 해도 쓸모없는 데이터이다.
가장 많은 실수 중 하나는 데이터를 만들 때부터 중요한 데이터 / 중요하지 않은 데이터와 같이 가치 판단을 해서 선별해서 만들려고 한다는 점이다. 그러나 데이터는 많으면 많을수록 좋고 데이터가 가지는 조건과 상황을 같이 고려한다면 우리에게 중요한 정보들이 만들어 질 수 있다. 따라서 데이터의 초기 생성 단계부터 데이터의 가치를 판단한다는 것은 다이아몬드 원석을 찾으면서 반짝이는 것만을 찾는 것과 비슷하다. 컴퓨터나 전자 기기가 많이 보급되지 않은 시절에는 어떤 데이터를 수집할 것인지 선택해야지만 한정된 자원으로 원하는 데이터를 모을 수 있었지만 이제는 그럴 이유가 없어졌다. 움직이지 않아도 내 곁에 있는 핸드폰은 끊임없이 내가 어디에 있고 (정확하게 핸드폰이 어디에 있고) 필요하다면 어떤 소리가 나는지 어떤 뉴스가 전달되는지 끊임없이 데이터를 주고 받는다. 그리고 그 데이터 안에는 이미 가공되어 가치가 있다고 생각되는 정보들도 많이 전달된다. 예를 들어 가치있다고 믿는 뉴스가 나에게 전달되었을 때 읽지도 않고 그냥 지워버렸다면 지워버리는 행동 안에도 사용자는 아주 잠깐동안 읽었다 (실제로는 읽지 않았다) 지워버렸다는 데이터가 발생하고 이 데이터를 사용자는 해당 뉴스에 대해서 관심이 별로 없다는 정보를 얻을 수 있다. 반복적으로 스포츠 뉴스에 대해서 읽지 않고 지워버린다는 행동들이 데이터로 모이게 된다면 해당 사용자는 스포츠에 대한 관심이 크지 않다는 정보를 얻게 된다.

이처럼 우리는 별 생각없이 움직이고 반응하고 행동하지만 이 모든 행동들은 핸드폰과 같이 수많은 센서들이 있는 기기를 통해서 상상하지도 못하는 수많은 데이터들이 만들어진다. 다른 예를 들어보자. 반대로 거의 모든 차량에 있는 영상기록장치 (블랙박스) 는 데이터인가 개인정보인가 묻는다면 거의 대부분은 개인정보라고 대답할 수 있지만 해당 영상기록이 누구의 것인지 모르게 인터넷에 그냥 떠돌아 다닌다면 그것은 개인정보이기 보다는 그냥 단순한 데이터라고 말하는 것이 더 정확할 것이다. 누군지 알 수 없고 그리고 특별한 사고 기록이 있어서 더 이상 알 필요가 없이 정상적으로 잘 주행한 영상기록이라면 개인정보의 가치를 가지지 않을 것이다. 다만 대부분의 영상기록 데이터는 누구의 것이라 내용을 알기 때문에 바로 '누구의 것'이라는 소유의 조건이 포함되어 개인정보가 되는 것이다.
Privacy manufacturer ...
소위 음란물 영상에서 사람들이 중요하게 생각하는 것이 무엇일까? 이 질문에 정확하게 대답하기 위해서는 음란물을 탐독하고 그들의 세상에서 접근하는 것이 중요하지만 그렇게 하고 있다고 해도 그렇고 그것을 위해 탐독한다고 해도 좀 그렇다. 간접적으로 알 수 있는 방법은 사람들이 많이 찾는 제목이나 내용을 통해서 찾아보는 것이다. 개인의 성적 흥분만을 위해서 음란물이 필요하다면 누군지 알 수 없이 알몸만 나온 영상으로 성적 행위를 보여주면 될 것같은데 음란물을 탐독하는 제목은 이상하게 등장인물에 더욱 집중하는 경향을 보인다. 인종별로 분류하거나 얼굴이 나왔는지 심지어 영상에서는 알 수 없는 두사람의 관계에 대해서도 친절하게 설명한다. 음란물의 가장 큰 문제는 결국 영상 데이터가 누구인지 특정될 identify 수 있는 개인정보가 된다는 점과 정확한지 알 수 없는 그리고 알 필요도 없는 수많은 잘못된 조건과 상황이 결합되어 막기 힘든 개인정보가 되어버린다는 점이다. 음란물이 사회적 문제가 된다는 공감대를 가지는 가장 큰 이유는 개인정보 뿐만 아니라 그 개인정보가 전달 속도와 힘이 무섭다는 점이다.
음란물은 아니지만 우리는 수많은 개인정보를 만들어 내고 있다. 개인은 단순히 데이터를 만들고 있다고 생각하지만 인터넷은 충분히 그런 데이터를 개인정보로 만들고 있다. 우리가 사용하는 많은 인터넷 서비스들은 다른 의미에서 우리가 의미없이 만들어내는 데이터들을 개인정보로 가공하는 공장과도 같다. 예를 들어 인스타그램 Instagram 에 수많은 사진들을 올린다. 올리는 순간에는 단순히 데이터지만 개인의 계정을 통해서 전달되기 때문에 자연스럽게 바로 개인정보가 된다. 반대로 개인을 특정하기 힘든 광고 목적으로 만들어진 계정에서 올린 데이터라면 개인정보라고 보기 어려운 데이터도 존재할 것이다. 자기 가족의 사진을 올리는 경우를 자주 볼 수 있다. 공개로 올린 단란한 사진들 속에는 누가 아버지고 누가 어머니고 누가 자식인지 모두 보여준다. 나쁜 맘을 먹는다면 아이들을 납치하고 정확하게 몸값을 요구해야 하는 부모가 누구인지 알 수도 있고 아버지를 납치하기 위해 자식이나 부인에게 가족여행 당첨되었다며 유인할 수도 있을지 모른다. 심지어 인스타그램을 포함한 많은 소셜 미디어는 태그를 통해서 더 특정할 수 있다. 예를 들어 #지역맘 과 같이 특정 지역이 포함된 그리고 육아를 시작한 인물들을 찾아내기 쉬울 뿐만 아니라 오히려 그렇게 찾도록 스스로 태그를 올리기도 한다. 마음만 먹는다면 특정 지역에 육아에 몰두하는 엄마를 찾을 수도 있고 자식이 어떻게 생겼는지도 쉽게 파악할 수 있다.

반대로 자신이 소비하고 즐기는 생활 수준을 자랑하고 싶을 수도 있다. 물론 그렇게 자랑하는 것이 나쁘다고 할 수 없지만 자랑하고 싶은 소비 수준뿐만 아니라 삶의 동선까지도 쉽게 노출시킨다. 어느정도 그런 부분을 노출시킬 수 밖에 없기도 하고 광고나 홍보 목적으로 사용한다면 적극 노출되게 해야겠지만 개인의 삶까지도 광범위하게 노출시켜야 하는지 의문스럽다. 오히려 그렇게 노출되는 범위는 결국 피해볼 수 있는 위험을 높여주기 때문이다. 미국의 정보기관에 들어간 기쁨에 자신의 계정에 정보기관 신분증을 공개된 계정으로 올린 정말 이해할 수 없는 사람이 있었다. 물론 그 기쁨과 함께 기관 신분증 이미지를 올린 것만으로 바로 해고되었지만 종종 출입증과 같이 중요한 정보를 가지는 데이터를 아무렇지 않게 올리는 사람들이 있다. 친절하게 자신의 사진이나 이름 정도는 지우고 올리기에 개인정보가 아닌 단순히 데이터라고 할 수 있지만 동일 기관에 대한 출입증 이미지만 모아보면 위조 신분증을 만들 수 있는 좋은 데이터가 될 것이다.
개인정보의 노출 위험성을 인식하고 조심하는 대표적인 경우가 택배 도착의 기쁨을 알리는 사진일 것이다. 열심히 자신의 주소, 이름 등 개인정보가 될 것 같은 부분을 열심히 지우고 올리지만 정작 바코드는 너무도 선명하게 보인다. 바코드를 읽어서 해당 택배 회사에서 송장번호로 검색하면 생각보다 많은 개인정보가 나온다는 것을 알게 된다. 열심히 숨겨온 개인의 주소도 노출될 수 있고 개인이 올리는 지역의 정보을 모아보면 개인의 동선 뿐만 아니라 조금 더 노력하게 된다면 개인 거주지까지도 알아낼 수 있다. 가끔 #삭제예정 이라는 태그로 올라오는 공개 사진들을 보면 자신의 계정에서 삭제되면 정말로 인터넷에서 삭제될 것이라고 믿는지 모르겠다. 여러가지 목적이 있지만 이처럼 인스타그램에서 공개된 사진들이 거의 실시간으로 수집된다. 그래서 #삭제예정 이지만 이미 #공개완료 라는 사실도 인식해야 한다.
What machine does better ...
인공지능 Artificial intelligence 이 관심의 중심에 놓이면서 항상 재미처럼 붙는 주제가 바로 인공지능이 빼앗아갈 인간의 직업이다. 어떤 직업은 인공지능에 의해서 사라지게 될 것이다. 어떤 분야는 인공지능이 인간보다 더 잘할 것이라고 예상하지만 아직 제대로 존재하지 않는 인공지능의 직업을 사라지게 할 것이라고 말하기도 한다. 인간의 관심사에는 어떤 직업 job 이 사라지게 되는지가 중요할 것이다. 인공지능의 시대에는 선택하지 말아야 하는 혹은 선택할 수 없는 직업이라고 생각하기 때문이다. 그러나 인공지능 더 현실적으로 보아서 직업의 관점이 아니라 작업 work 더 구체적으로는 작업내용 workflow 의 관점에서 생각해 볼 필요가 있다. 알파고 AlphaGo 가 보여준 것처럼 인간과 기계의 대결에서 누가 이기는지가 중요한 것이 아니라 기계가 인간보다 더 잘하는 내용을 찾아야 하는 것이다. 그리고 기계가 잘하는 작업내용을 통해서 기계에게 양보해야 할 내용은 무엇인지 인간이 계속 해야만 하는 것이 무엇인지 결정해야 한다.
우선 인간의 의사 결정 decision making 과정이 정말 논리적이고 합리적인지 생각해 보자. 회사의 최고 경영자나 나라의 지도자 아주 사소한 결정을 내려야 하는 위치에 있는 어떤 사람들도 자신의 선택이 항상 합리적이라 모든 이들이 이해하고 따를 수 있기를 바라지만 현실의 많은 부분은 그렇지 않다. 처음부터 인간의 의사 결정 과정이 정말 합리적인지 의심해야 한다. 많은 자료를 모으고 어떤 결정이 가장 최선의 결과를 얻을 수 있는지에 대해서 고민하지만 종종 인간의 결정은 아주 사소한 그리고 감정적인 선택을 하게 되는 경우를 종종 보게 된다. 단적으로 모든 인간이 객관적 자료에 의해 합리적으로 모두 결정하게 된다면 누군가를 설득시키는 작업도 회사에서 마케팅의 역할도 크게 필요하지 않을 것이다. 그러나 합리적 판단을 위한 충분한 자료 혹은 데이터를 얻지 못하는 경우도 존재하고 잘못된 데이터 혹은 목적을 가지는 데이터를 통해서 잘못된 선택을 하게 되기도 한다. 경영을 잘하기 위해서 도입되는 경영정보시스템 MIS: Management Information Systems 부터 의사결정지원 Decision making support 시스템은 사실상 인간이 좀 더 합리적으로 판단하기 위해서 필요한 데이터를 어떻게 잘 모을 수 있는지 도와주는 것이다. 그러나 결국 마지막 선택은 그 모든 데이터와 분석에도 불구하고 인간이 한다.
 |
| 출처: IoT for all - https://www.iotforall.com |
그래서 모든 직업에서 이루어지는 구체적인 작업내용 workflow 상에서 데이터를 모으고 분석하는 단계는 기계가 인간보다 더 잘할 수 있다고 생각했다. 그러나 현실적으로 그 모든 데이터들은 대부분 인간이 입력해야 하기 때문에 어떤 데이터를 입력하게 되는지도 인간의 의도 bias 가 들어가게 되었다. 그래서 인간은 데이터를 입력하기 보다는 무엇인가 가치판단이 포함되어 선택된 정보가 입력되기 쉬었다. 즉, 인간에게 가치있어 보이는 정보를 만들기 위한 수많은 데이터들은 인간이 보고, 듣고 (혹은 느끼고) 판단하고 필요한 정보로 만들어서 가공해서 만드는 작업을 중요하게 생각했다. 수많은 데이터가 아닌 인간이 한번 분석해준 정보로 판단하고 싶은 것이다.
예를 들어 '요즘 유행하는 혹은 앞으로 유행할 패션은 어떤 것인가?' 라는 질문을 받게 된다면 패션 종사자들은 사람들이 입고 다니는 옷들부터 전문가들의 의견 등 다양한 데이터 혹은 정보를 얻어 결론을 내고 싶을 것이다. 그러나 만약 분석하려는 인간이 자신이 자주 다니는 장소만으로 선택해서 이 지역이 유행하면 전국적으로 유행할 것이라는 가정을 통해서 한 지역만을 조사하거나 인터넷에 나오는 많은 패션 사진을 찾아 보지만 실제로 자신의 기호 혹은 선호도 preference 없이 객관적으로 사진을 모을 수 있을지 그리고 그 결과가 어떨지는 알 수 없다. 그러나 기계가 이런 작업을 수행하게 한다면 최근 패션에 관련된 사진들과 소셜 미디어에 올라오는 사람들의 일상 속에서의 패션들을 모아서 옷에서 나타나는 수치들 예를 들어 원피스의 경우 위와 아래가 구분되는 비율이나 옷의 형태뿐만 아니라 일상에서 어떤 옷을 입고 어떤 장소에 자주 간다와 같이 옷 뿐만 아니라 관련된 배경정보들까지도 포함해서 포괄적인 데이터를 분석할 수 있다. 뿐만 아니라 거의 실시간으로 데이터를 추가할 수 있기도 하고 인간이 궁금해 하는 부분들도 바로 분석할 수 있는 능력을 가진다. 기계가 인간보다 충분히 잘 할 수 있는 부분은 데이터가 많아진다면 그 데이터를 모아서 인간이 원하는 질문에 대답하기 위한 시간이 절약된다. 예를 들어 야외에 나갈 때 선호하는 패션은 무엇인지 물어본다면 인간은 다시 야외라는 조건을 포함해서 해당되는 데이터를 다시 보아야 하겠지만 기계에게는 그런 데이터를 처리하는 시간뿐만 아니라 결정적으로 인간이 제시할 수 있는 다소 모호한 그리고 광범위한 대답 예를 들어 "내년에는 무채색의 정장 스타일..." 과 같은 내용이 아니라 기계는 명도 채도 그리고 스커트의 길이는 어떤 비율과 같이 수치화 된 quantified 새로운 정보를 제시할 수 있을 것이다.
 |
| A P P A R E L – Clothing in the age of data accumulation and machine learning. 원문: https://meson.in/2s1GV4x |
결국 기계가 인간보다 더 잘 할 수 있는 작업내용을 생각해보면 역시 데이터를 얻어내고 분석하고 이를 수치화 하는 작업을 우선 생각할 수 있다. 역시 좋은 목적으로 기계의 수집, 분석 능력을 사용할 수 있지만 개인이 인지하지 못하고 만들어 내는 수많은 데이터를 개인정보로 만들어 내는 작업도 분명 기계가 탁월하게 할 수 있을 것이다. 예를 들어 특정 인물이 어떤 곳에 살고 있고 가족 관계가 어떻게 되고 아이는 어떤 유치원에 다니는지 우리는 수작업으로 관음증 환자처럼 찾아내야 하는 작업들을 기계는 아주 쉽게 그리고 죄책감도 거의 가지지 않고 쉽게 할 수 있을 것이다.
Such a trivial data ...
대한민국은 주민등록 번호 하나로 수많은 개인정보를 얻어 낼 수 있는 무서운 국가 중 하나이다. 물론 국가가 국민을 쉽게 통제할 수 있는 수단으로 그리고 어떤 측면에서는 범죄자를 쉽게 찾아낼 수 있는 좋은 수단이라고 변호할 수 있지만 범죄자를 위해서 수많은 비범죄자의 개인정보까지 들춰질 권리까지 국가가 가져야 한다고 주장할 수 없다.
한국에서는 수많은 카페나 공공장소에서 인터넷을 쓸 수 있다. 예를 들어 카페에서 접속할 수 있는 소위 비밀번호 (정확한 의미에서 비밀번호는 아니다.) 를 입력하면 무선인터넷을 사용할 수 있다. 그러나 그와 함께 카페의 내부 인터넷에 들어갈 수 있다 혹은 공유기에 접속한다는 말이다. 그리고 공유기 관리를 위한 페이지에 접근할 수 있다. 공유기의 관리자 암호/패스워드가 기본값이라면 카페 관리자가 아니라도 쉽게 관리화면에 들어가서 수많은 설정을 바꿀 수 있다. 이론상 (그리고 현실상) 외부에서도 접근이 가능하다는 말이다. 그리고 공유기 설정값이 기본값으로 되어 있다면 수많은 공유기에 접근해서 원하는대로 설정을 바꿀 수 있다. 가장 쉽게 DNS 를 바꾸는 것을 생각할 수 있다. DNS 는 인터넷의 주소록이다. [ 인터넷의 주소록 DNS 서비스 ─ 기반기술에 대해서... ] 예를 들어 은행 업무를 위해서 yourbank.com 을 입력할 때 해당 도메인 이름이 어디에 있는 서버인지 알려주는 주소록이 DNS 인데 이 DNS 에서 yourbank.com 가 자신들이 만든 은행처럼 보이는 곳으로 알려주어 접근하게 한다. 잘못된 DNS 정보로 들어간 사용자는 자신은 은행업무를 본다고 생각하지만 가짜 은행 사이트에서 자신의 개인정보를 입력하게 된다.
 |
| 일반 가정집에서 사용하는 공유기에 중국 (124.94.30.252) 에서 들어오려고 한다. 공유기의 비밀번호 기본값을 통해 들어오려는 시도를 쉽게 볼 수 있다. |
실제로 내부 인터넷에 들어간다는 것은 외부에서 접근하는 것과는 차원이 다른 많은 부분들이 노출될 수 있다. 대표적으로 CCTV 도 들어가서 볼 수 있다. 인터넷을 제공하는 많은 곳에서 이처럼 자신의 공유기를 제대로 관리하지 않거나 CCTV 도 쉽게 기본값으로 들어갈 수 있는 곳을 자주 볼 수 있다. 종종 이런 이야기를 해주지만 대부분의 반응은 "별로 중요한 것도 없는데요." 혹은 "뭐 볼게 있겠어요." 라고 크게 무서워하지 않는 경우가 대부분 이었다. 그러나 대한민국이 아닌 다른 나라에서 이런 가능성에 대해서 이야기하면 상당 부분 놀라는 경우가 많았고 싱가포르와 같은 나라는 자신의 인터넷을 공개하거나 이렇게 위험에 노출시키면 안되도록 규제하고 있다. 권한이 없는 혹은 주인이 아닌 사람이 들어와서 영상 자료를 보는 것이 무엇이 문제일까 싶지만 개인적으로 생각한 창의적인(?) 생각은 노트북 쓰는 사람의 화면이나 키보드 입력 모습을 통해서 충분히 암호도 알아낼 수 있을 것이라고 생각했다. 실제로 공공장소에서 전혀 모르는 사람이 누구인지 그 사람의 소셜 미디어 계정을 찾아내는 방법은 다양하다. 책에 적어놓은 학번 / 이름 을 통해서도 알 수 있고 옆자리에 앉아 로그인하는 화면에서 이름이 누구인지 알 수도 있고 가끔 거울이나 물건 등에 반사되어 보이기도 한다. 지하철에 서서 가면 앞에 앉아 있는 사람이 무엇을 하고 있는지 시력이 좀 더 좋다면 그 사람의 계정 이름도 알아낼 수 있다.

유명한 사람도 아니고 내 개인정보가 뭐 중요하겠어 라고 생각할 수 있다. 대규모 서버에 공격하는 사람들도 많지만 의외로 전혀 들어올 이유가 없는 아주 사소한 서버에도 공격하는 사람들이 많다. 우리가 느끼지 못할 뿐이지 정말 정체를 알 수 없는 수많은 공격자들은 개인 서버인지 그냥 가정집 공유기인지 생각하지 않고 무조건 공격하는 경우를 자주 볼 수 있다. 개인적으로 관리하는 곳들은 모두 공유기에 접근하려다 실패하는 내용을 보지만 만약 공유기 관리 화면에 기본값으로 접근할 수 있다면 아마 공격자들이 의도한대로 접근해서 자신들이 원하는 작업을 했을 것이다.
How to protect privacy ...
무선랜을 사용하기 위해서 무선랜 비밀번호를 입력한다고 말하지만 정확히 이는 비밀번호는 아니다. 내가 접근하고 싶은 무선랜 이름 (SSID: service set identifier) 를 선택하면 네트워크 보안 키 를 입력하라고 나온다. 소위 '무선랜 비밀번호'는 키 key 이다. 간단하게 설명하면 우리가 입력하는 '비밀번호'는 무선랜을 써도 좋다는 허락을 위한 암호가 될 수도 있지만 사용자의 기기와 공유기가 데이터를 주고 받을 때 전달되는 데이터가 암호화가 될 수 있는 열쇠와 같은 것이다. 예를 들어 내가 데이터를 보낼 때 가장 먼저 공유기에 전달이 되어야 하는데 공유기에 전달되기 전에 내가 보내는 데이터를 '미리 정한(공유한) 키 Pre-Shared Key' 를 통해서 암호화를 해서 보내니 공유기 너는 이 키를 가지고 암호화한 데이터를 풀어서 받아 라고 규칙을 정한 것이다. 간단히 정리하면 사용자의 기기와 공유기 사이에 전달되는 데이터가 암호화하기 위한 것이다. 그래서 공개되어 '비밀번호가 없는' 무선랜은 그 사이에 전달되는 데이터가 암호화되지 않은 상태로 전달된다는 것이다.
데이터가 암호화되고 암호화되지 않은 것에 대해서는 조금은 민감할 필요가 있다. 옛날에는 안방에서 엄마가 전화하고 있으면 다른 방에서 수화기를 몰래 들어 통화를 감청(?)할 수 있었다. 마찬가지로 두 사람이 통화하는 중간 어딘가 똑같이 신호를 받아서 들을 수 있다면 같은 집 수화기를 통하지 않고도 들을 수 있다. 인터넷 데이터도 마찬가지이다. 암호화되지 않은 데이터는 어딘가에서 똑같이 받을 수 있다. 즉, 전달과정에서 동일한 데이터를 여러 곳에서 얻게 된다. 암호화가 되지 않았다면 내가 보내는 데이터 - 채팅 내용, 비밀번호, 주소록 등 - 모든 데이터 내용이 그대로 알아 볼 수 있는 형태로 얻게 된다. 그러나 만약 보내는 A 와 받는 B 둘만이 어떤 키를 가지고 있고 A 가 그 키를 통해서 보내는 데이터를 암호화해서 보내고 B 는 받은 데이터를 미리 공유된 키를 가지고 암호를 풀면 (복호화) 아무리 중간에 데이터를 얻게 된다고 해도 중간에서 데이터를 몰래 볼려고 한 사람은 암호화되어 알아낼 수 없는 데이터만 얻게 되는 것이다. 그래서 공개된 무선랜에 접속해서 인터넷을 쓴다는 것은 최소한 같은 공유기 내에 있는 사람에게는 암호화되지 않은 데이터를 누군가 몰래 볼 수 있다는 말이다.

인터넷에서 데이터 암호화는 상당히 중요하다. 그래서 이제는 거의 모든 웹서비스는 기본적으로 데이터 암호화 기술을 적용해서 사용하게 한다. 인터넷 주소창에 http:// 로 시작하는 주소와 https:// 로 시작하는 주소를 볼 수 있다. http:// 는 공개된 무선랜이라 생각하면 된다. https:// 는 사용자와 서버 사이의 데이터를 암호화해서 전달한다고 생각하면 된다. 다시 말해 http:// 를 보고 입력하는 정보들은 전달되는 과정에서 암호화되지 않은 상태 그대로 누군가에 의해 노출될 수 있다. 반면 암호화가 되어 있는 서버 사이에서는 내가 입력한 정보들은 암호화가 되어서 중간에서 데이터를 가져가도 암호화된 데이터만 가져가 제대로 된 키가 없다면 제대로 된 정보를 얻어낼 수 없다. 그래서 암호화된 주소 https:// 를 가지는 웹서비스만 사용하도록 습관을 가지는 것이 좋다. 조금만 관심을 가지고 보면 알겠지만 대부분 주요 서비스들은 암호화는 기본이고 데이터 암호화 통신의 중요성을 인식하고 있는 단체를 중심으로 개인들도 암호화를 쉽게 그리고 비용없이 적용할 수 있도록 도와주고 있다. 가장 대표적인 곳이 Let's Encrypt 이고 개인도 간단한 설정만으로 적용할 수 있다. 그리고 많은 기업들은 데이터 암호화가 기본이 될 수 있도록 필요한 비용과 지원을 하고 있다. 그만큼 우리가 일상적으로 사용하는 데이터가 누군가에 의해서 탈취당해서 악의적으로 사용될 가능성, 아무리 '사소한' 개인의 데이터라고 해도 보호되어야 한다는 철학을 가지고 있는 것이다.

데이터 암호화가 적용되었는지 아닌지 살펴보면서 인터넷을 돌아다니다 보면 대한민국의 주요 기업들은 여전히 부족하다는 것을 알게 된다. 심지어 인터넷이 사업의 중심인 회사들조차도 자신의 서비스를 제대로 된 암호화를 제공하지 않고 서비스하는 것을 볼 수 있다. 알 수 없는 회사의 심오한 경영 철학이 있다면 할 수 없지만 개인 데이터의 중요성을 누구보다 잘 알고 있고 그런 사용자의 데이터가 어떤 기업보다 기업 경영의 자산인 기업에서 이렇게 보호되지 않는 웹서비스를 한다는 것은 조금 이해하기 어렵다. 뭔가 이해할 수 없는 심오한 그리고 기술적 진보로 암호화되지 않은 인터넷 환경에서도 개인의 데이터를 보호할 수 있는 최첨단 기술이 존재할 것 같지도 않다.
Less better than more ...
보안에서 한가지 원칙은 자신의 민감한 정보들은 자주 입력하지 않는 것이다. 예를 들어 브라우저에 비밀번호를 저장하고 들어갈 때마다 브라우저에서 비밀번호를 넣어주는 것과 들어갈 때마다 사용자가 비밀번호를 입력하는 것 중에서 어떤 것이 더 안전한지 묻는다면 대부분 브라우저에 자신의 비밀번호가 저장되어 있다는 사실때문에 매번 비밀번호를 입력하는 것이 더 안전할 것이라고 생각할 수 있다. 그러나 사용자가 키보드나 터치스크린을 통해서 입력하는 과정에서 발생할 수 있는 시각적인 해킹 - 사용자가 키보드를 입력하는 움직임을 통해서 비밀번호를 알아내는 - 이나 키보드 로그 - 키보드의 기록값을 몰래 저장하는 - 를 통해서 유출될 가능성이 있다. 그러나 브라우저에 저장된 비밀번호를 바로 암호 입력부분에 넣게 된다면 최소한 키보드 입력에 의한 위험성은 줄일 수 있다. 그러나 여기에서 더 중요한 부분이 있다. 사용자가 기억할 정도의 비밀번호는 두가지 위험성을 동시에 가지고 있을 가능성이 높다. 첫번째는 자주 쓰는 비밀번호가 한두개 정도 심지어 아예 동일한 비밀번호를 사용하고 있다면 다른 웹서비스에서 유출된 비밀번호가 바로 다른 웹서비스에서 사용될 수 있게 된다. 그리고 사용자가 입력을 매번 할 수 있다는 것은 사용자가 기억하고 있다는 것이다. 사용자가 기억할 수 있는 memorable 비밀번호란 어느정도 유추할 수 있는 비밀번호일 가능성이 높다.

그래서 비밀번호는 아예 사용자가 모르는 것이 가장 안전할 수 있다. 문제는 자신의 비밀번호인데 자신이 모르고 기억하지 못한다는 것이 말이 안되는 소리같다. 브라우저가 비밀번호를 저장하고 있듯이 비밀번호만 대신 저장해서 관리해주는 프로그램도 가능하다. 접속하는 웹서비스에 맞는 사용자 이름 / 비밀번호를 저장하고 있다가 필요한 항목에 사용자 이름 / 비밀번호를 대신 입력해주는 것이다. 사용자가 입력할 필요가 없다. 만약 각 웹서비스 별로 비밀번호를 저장할 수 있다면 비밀번호를 기억할 필요도 없고 얼마든지 길게 그리고 복잡하게 비밀번호를 입력해도 괜찮다. 다만 비밀번호를 관리하는 프로그램을 실행시키기 위한 비밀번호는 기억하고 입력해야 할 것이다. 모든 웹서비스의 비밀번호가 모두 다르다면 한 웹서비스에서 유출된 자신의 비밀번호를 걱정할 필요가 없을 것이다. 유출된 비밀번호를 통해 다른 웹서비스에 들어갈 수 없기 때문이다. 좀 더 보안에 신경쓰기 위해서는 2차 인증 2-step verification 을 사용하는 것이다. [ 인터넷 보안 - 나의 계정을 지키자 ]
공용 컴퓨터를 자주 사용하기 보다는 정해진 기기에서만 접속할 수 있다면 좋을 것이다. 자주 개인정보가 입력될 수록 분명 노출될 가능성은 높아지기 때문이다. 공용 컴퓨터는 특히 어떤 악의적인 프로그램이 설치되어 있을지 데이터 전달을 위한 안전한 환경인지 확인할 수 없기 때문이다. 인증을 위한 다양한 방법을 제시하는 것도 좋다. 로그인을 하면 2차인증을 통해서 다시 한번 확인할 수 있지만 등록된 스마트폰에 간단한 메세지를 보내 로그인을 위해 확인하는 방법도 있고 확인 메일을 보내서 메일에 포함된 확인 주소를 통해서 인증해서 들어갈 수 있다. 모든 방법들은 사용자의 편의를 위한 부분도 있지만 만약 비밀번호가 유출되었다고 해도 본인을 인증할 수 있는 다양한 방법으로 본인이 아닌 다른 사람의 접근을 막기 위해서이다. 사실 2차인증도 완벽하게 안전하다고 말할 수 없다. 가장 창조적인 방법으로 이미 유출된 개인 아이디와 비밀번호를 통해서 접근을 하고 SMS 로 2차인증 번호를 보내주는 계정의 통신사 SMS 서버를 해킹해서 중간에 2차인증 번호를 받아서 이를 입력해서 들어간 경우도 있었다. 더 강화된 다양한 기술을 적용하지만 최소한 진짜 사용자가 접근하는 모든 방법을 그대로 수행한다면 들어가는 것을 막을 수는 없을 것이다.
그렇다면 이렇게 애쓰며 남의 계정을 들어가려고 하는 것일까? 그 속사정을 알수는 없지만 무엇인가 이득이 있기 때문에 그렇게 애쓴다고 할 수 있을 것이다. 가장 쉽게 볼 수 있는 경우는 광고용으로 사용하기 위해서 타인의 계정에 들어가는 것이다. 이미 만들어진 계정이고 자신의 신분을 효과적으로 숨길 수 있고 유출된 비밀번호라면 특별히 계정을 만드는 것보다 더 안전하기도 하기 때문이다. 그리고 자신의 계정으로는 쉽게 올리기 힘든 강도높은(?) 광고들도 올리고 계정이 삭제되더라도 괜찮기 때문이다. 그리고 여러개의 계정을 가진다는 것은 그만큼 접속 회수를 늘릴 수 있는 도구로 사용될 수 있다는 것이다. 이해할 수 없지만 좋아요 ♥ 가 많이 달린 개시물에 대해서는 알 수 없는 신뢰를 보인다. 다수가 좋아하는데 무슨 문제있겠어 혹은 다수가 인정하니깐... 과 같은 요소는 우리가 냉정하게 판단하기 보다는 처음부터 편향된 방향으로 생각하기 쉽도록 만들거나 특별히 큰 관심을 가지지 않는 부분도 거의 유일하게 신뢰할 수 있는 것은 다수의 긍정이라는 사실이라고 믿기 때문에 타인의 수많은 계정을 동원해서 좋아요 숫자만 올리는 것으로 광고효과가 좋다고 믿는 이들에게는 다수의 계정을 확보하는 것이 중요할 것이다.
Data is flowy ... Information is ...
우리가 인식하지 못한 상태에서 수많은 데이터를 만들어 내고 있고 그 데이터는 우리의 의도와는 다르게 사용되기도 한다. 그 모든 순간에도 생각해 볼 부분은 바로 데이터는 흐름이라는 점이다. 숫자 혹은 단순한 문자에 불과하다고 생각할 수 있지만 데이터는 흐름이 존재할 때 더 많은 가치를 가질 수 있는 가능성을 가지게 된다. 그래서 많이 사용되는 데이터일 수록 정보에 더 많은 영향을 줄 수 있는 가능성이 높고 그만큼 중요한 데이터가 될 수 있다. 그래서 데이터는 가치판단 뿐만 아니라 옳고 그른 판단을 내릴 수 없다. 숫자 3.141595 가 나쁘다라고 말할 수 없기도 하지만 심지어 '살인'이라고 해도 '가족을 지켜내기 위해서 강도를 살인하다' 라고 한다면 살인 하나만으로 나쁘다고 말할 수 없기 때문이다.
그만큼 데이터란 우리에게 알려주는 정보의 단편 혹은 아직 분석되지 않은 사실의 흐름일 뿐이지 그 데이터가 우리에게 좋다 나쁘다를 말해줄 수 없다. 문제는 데이터를 어떻게 관리하고 어떻게 통제하는가의 문제이다. 유리한 데이터만 보여주고 불리한 데이터는 감춘다고 해도 데이터는 흐름을 가지기 때문에 데이터의 흐름이 끊어진다면 우리는 그 데이터를 신뢰할 수 없게 된다. 큰 범위에서 의도적으로 조작된 데이터는 항상 스스로 잘못된 부분을 알려주기 마련이다. 일부러 감추려는 데이터는 그 흐름이 인위적으로 끊길 수 밖에 없기 때문이다. 이러한 데이터의 특징을 잘 모르고 감추기 위해서 데이터를 조작하거나 숨기는 것은 자신에게 유리한 / 불리한 데이터가 존재한다고 가치판단을 하기 때문이다. 조작된 데이터를 보여줄려고 한다면 차라리 아무것도 공개하지 않는 것이 숨기려는 자들에게는 최선의 선택이라는 것 아니면 모든 것을 그대로 밝히는 것이 가장 좋을 것이다.

그래서 데이터란 숨기고 보여주지 않으려고 하고 데이터의 관리를 통제하려고 하는 것보다 투명하게 공개하는 것이 중요하다. 그런 의미에서 있는 그대로의 데이터와 그 데이터의 흐름을 숨기지 않으려는 것을 투명성 transparency 라고 한다. 2000년대 말 사용자의 개인정보를 관리하는 기업 특히 구글을 중심으로 해서 데이터의 투명성이 중요하다고 강조했다. 구글 투명성 보고서 페이지에 소개된 투명성에 대한 간단한 설명은 다음과 같다.
"정부 및 기업의 정책과 조치가 개인정보 보호, 보안, 정보 이용에 미치는 영향을 보여주는 데이터를 공유합니다."
"Sharing data that sheds light on how the policies and actions of governments and corporations affect privacy, security, and access to information."
결과적으로 공유 (제공) 하는 것은 데이터이다. 그 데이터의 성격은 정부 및 기업의 정책과 조치가 개인정보, 보안, 정보 이용에 미치는 영향을 보여준다. 간단하게 설명하면 정부가 요구해서 어떤 범죄 의심자의 위치, 지역이나 관심 분야 등과 같은 개인정보를 얼마나 제공했는지 그리고 그 이유는 무엇이였는지 알려주는 것이다. 그리고 어떤 이유에서 개인이 올린 데이터를 삭제했는지 서비스 장애에 의해서 개인이 제대로 데이터를 관리할 수 없는 순간은 없었는지 보고하는 것이다. 다양한 내용들이지만 서비스 전반에 걸친 모든 데이터의 흐름이 어떻게 진행되고 있는지 데이터의 흐름에 영향을 줄 수 있는 모든 상황 / 조건을 공개한다는 것이다. 중요한 점은 데이터의 흐름을 막거나 통제하는 것이 아니라 가급적 데이터가 잘 흐를 수 있도록 하고 그 과정에서 그 흐름을 막거나 바꿔야 하는 경우가 있었다면 그 이유와 결과를 보고하는 것이다. 따라서 투명성이란 개인정보가 어떻게 어디로 흘러갈 수 있는지 확인할 수 있는 중요한 부분이다.
NGO 단체인 국가투명성기구 (Transparency International) 는 국가의 청렴도 반대로 부패지수를 발표한다. 부정부패는 사회나 국가에서 인간을 억압하고 고통을 주는 요소라고 생각한다. 정직하게 생각하고 이를 행동하려고 해도 부정부패가 만연해 있다면 제대로 자신의 양심대로 살아가기 어려울 뿐만 아니라 대부분 희생자가 될 것이라는 점이다. 그리고 부정부패의 가장 큰 적은 부정부패의 상황을 제대로 밝히지 않고 숨기기 때문이라고 보았다. 그래서 국가의 투명성은 부정부패의 정도를 알려서 얼마나 많은 비정상이 존재하는지 알리는 것이라고 본다. 웹서비스도 비슷하다. 좋은 웹서비스가 존재하고 사용자들이 잘 사용해 유용하다고 해도 자주 서비스가 중단되거나 소수의 이익만을 위해서 운영되면 안되기 때문이다. 어떤 문제도 발생하지 않는다면 좋겠지만 완벽할 수 없다면 문제가 되는 부분을 공개하는 것이다. 그리고 문제가 되는 부분을 투명하게 사용자들이 알게 된다면 자신이 사용중에 발생한 문제가 자신의 문제인지 서비스의 문제인지 파악할수도 있을 것이다. 투명성이란 모든 이들이 사용하는 서비스 그리고 그 과정에서 발생하는 모든 데이터에 대한 흐름을 파악할 수 있도록 해줘야 한다는 생각이다.
GDPR ...
요즘은 메일함에서 GDPR 에 대한 메일을 쉽게 본다. GDPR 는 General Data Protection Regulation 의 약자로 유럽연합이 유럽전역을 우선 대상으로 적용하는 '일반 개인정보보호 규정'이라 부른다. 그러나 General 을 그대로 해석해 일반이라고 표현하지만 적극적으로 일반이 아닌 '모든' 혹은 '통상' 이라고 부르는 것이 더 정확할 것 같다. 다시 말해 특별한 조건이 붙지 않는다면... 데이터의 관리, 처리에서 발생하는 문제는 누구의 책임인지 그리고 그 역할에 대해서 정의내리고 있다. 물론 유럽연합에 적용되는 규정이기 때문에 타 지역에서 지키지 않아도 되겠지 싶지만 데이터는 흐름이고 그 흐름에는 특별히 국경의 의미가 존재하지 않는다는 점 그리고 전략적으로도 유럽은 상당수의 데이터의 관리 주체라는 점에서 실질적으로 유럽연합의 적용은 전세계의 적용이나 다름없다. 뿐만 아니라 이 규정에서는 우선적으로 '확장된 영토 적용 범위'를 통해서 지리적 구분이 중요한 것이 아니라 데이터의 흐름이 중요하다고 강조하고 있다.

GDPR 에서 제시하는 중요한 개념에는 Controller 와 Processor 가 있다. Controller 는 '정보통제자' 혹은 '정보관리자' 라고 해석하기도 하고 Processor 는 '정보처리자' 혹은 '정보가공자' 라고 해석하기도 한다. 그냥 컨트롤러 / 프로세서 라고 그대로 쓰기도 한다. 한국어 번역의 기본 내용이 없어 그대로 컨트롤러 / 프로세서로 표현한다. 컨트롤러란 개인정보를 포함하여 개인이 만들어내는 데이터의 수집, 관리 그리고 광범위한 범위에서의 삭제까지 포함하는 데이터 / 개인정보를 어떤 방식으로 관리해야 하는지 책임의 범위를 확대했다. 개인 계정의 해킹에 의해서 노출된 개인정보라면 그 책임이 누구에게 있는지 범위를 확대하고 컨트롤러가 다양한 수단을 사용하려고 노력했지만 어쩔 수 없음을 증명하지 못한다면 컨트롤러의 책임이 있다는 점을 강조했다. 프로세서는 개인정보를 분석, 가공하는 과정에서 필요한 원칙과 역할을 제시했다. 그리고 무엇보다 어떤 과정에서 개인정보 유출되었을 때 적절한 통지를 해야한다. 예전에는 투명성을 통해서 데이터의 흐름을 파악할 수 있도록 했다면 GDPR 이후에는 개인정보가 유출되거나 남용되는 순간에 개인이 바로 알 수 있도록 알려야 한다. 그래서 개인정보의 주체는 권리가 확대되어 개인이 필요하다면 자신의 개인정보의 보관 삭제에 대한 적극적인 권리를 행사할 수 있도록 보장한다. 즉, 개인정보를 지우고 싶다면 개인정보를 보관, 관리, 가공하는 주체들이 이를 실행하고 이 결과를 개인에게도 알려야 한다.

이 정도 내용이라면 개인의 권리는 증가하고 기업은 불리해지는 것은 아닐까 생각하지만 중요한 점은 개인이라도 충분히 컨트롤러나 프로세서가 될 수 있다는 점을 생각해야 한다. 만약 내가 인터넷에서 우연히 얻은 개인정보를 통해서 분석을 한다고 해도 그 개인정보의 주체가 요구한다면 아무리 상업적 목적이 아니라도 그 요구를 들어주어야 한다. 심지어 개인 서버를 운영하고 있고 개인이 접속해서 남긴 다양한 개인정보 - IP 주소, 지역 등 - 에 대해서 수집하는 순간 개인도 컨트롤러가 바로 된다. 결국 기업 / 개인을 위한 규정이 아니라 어떠한 데이터를 얻고 처리하고 살아가야 한다면 이 규정에 적용받지 않을 수 없다는 것도 인식해야 한다. 결국 개인정보에 대한 중요성을 강조하게 되면서 수많은 데이터의 흐름에 대해서 민감하게 인식해야 하는 세상이 되었다.
Cannot be too sensitive ...
전세계의 거의 모든 데이터를 감시하고 테러와 같은 위험을 알아내서 미리 막을 수 있다면 자신의 개인정보도 기꺼이 제공할 수 있는지 묻는다면 어떻게 대답할 것인가? 역설적으로 데이터를 통해서 테러를 막을 수 있다는 생각은 실제로 데이터가 얼마나 중요한 것인지 심지어 현실에서의 행동까지도 미리 막을 수 있다는 뜻이고 이는 데이터 그리고 개인정보는 우리가 생각하는 것보다 높은 생명력(?)을 가지고 있다는 뜻이다. 개인정보는 우리의 삶과 연결되기도 하고 나쁜 목적이라면 한사람의 삶까지도 좌우할 수 있는 무서운 정보이다.
실제로 온라인에서만 이야기를 나누던 상대방에게 화가 나서 마음 먹고 상대방의 실제 거주지와 동선을 파악해서 살인을 했다는 이야기부터 앞서 이야기한 것처럼 가족관계나 사람들에게 협박이 될 수 있는 다양한 정보들을 통해서 두려움에 떨게 만들 수 있기 때문에 개인정보는 충분히 생명력을 가지고 있다. 그리고 생명력이란 타인에게 위협이 될수도 있고 실체하는 physical 위험이 될 수 있기 때문에 스타워즈 1편의 제목인 '보이지 않는 위험 The Phantom Menace' 이 될 수 있다. 현실에서도 인간을 가장 두렵게 만드는 것은 당장 눈앞에 있는 공포나 위험일 수 있지만 단순한 정보 그리고 그 정보에서 나오는 가능성이 큰 공포와 두려움을 만든다. 그리고 인간은 그 공포와 두려움을 피하기 위해서 비논리적인 행동도 하게 된다.

그래서 우리의 개인정보들에 대해서 아무리 민감하게 생각해도 지나치지 않는다. 물론 지나친 생각으로 그 자체가 두려움이 되어 공포 안에서 살아가라는 뜻이 아니라 잘 대처하기 위해서 데이터의 본질과 흐름을 파악하고 개인정보가 어떻게 만들어지고 어떻게 노출될 수 있는지 상식처럼 알아 놓는다면 자신도 모르는 본인의 개인정보로 피해를 보기 전에 대처할 가능성이 높아질 것이다.
Who owns privacy ...?
개인정보는 누구의 것인가? 개인이 보관하고 관리하는 개인의 것이지만 프로세서 Processor - 정보가공자가 만들거나 찾아낸 혹은 분석해서 밝혀진 개인정보라면 그 정보는 누구인지 설명하기 어려울 때가 있다. 예를 들어 자신이 올린 위치 정보가 없는 사진들을 통해서 누군가 사진의 배경이나 주변 정보를 통해서 '누가 사는 곳은 어디이다' 라는 개인정보를 알아냈다면 해당 개인정보는 누구의 것인지 생각해야 한다. 즉, 데이터가 수없이 만들어지고 데이터가 가공되는 과정에서 해당되는 개인들도 인식하지 못하는 정보들은 누구의 것이며 만약 분석한 주체와 상관없이 해당 개인정보 당사자의 것이라고 한다면 당사자는 어떻게 자신도 모르지만 만들어진 개인정보가 있는지 그리고 삭제하고 싶다면 어떻게 할 수 있는지 쉽지 않은 문제이다.
그래서 소위 '잊혀질 권리'를 이야기하지만 정작 잊혀질 권리를 주장할 수 있는 개인정보가 어디에 어떻게 저장되어 있는지 본인도 제대로 확인할 수 없고 검색되지 않는 개인정보는 처리할 수 있는 방법이 없다. 그렇기 때문에 개인정보를 관리하고 가공하는 주체를 나누고 각자의 역할과 책임을 설명하고 있는 유럽연합의 GDPR - 일반 개인정보보호규정 은 지키지 못하거나 책임을 다하지 못한 상황에서 과징금이나 개인 피해에 대한 보상 규정도 포함한다. 그러나 실질적인 문제는 자신이 관리하지도 않는 개인정보를 어디에 있는지 알기 어렵다. 예를 들어 환자의 임상 데이터를 모아서 의학 발전에 도움이 되도록 모을 때 환자가 누구인지 알 수 있는 내용을 제거해서 개인정보였던 내용이 임상 데이터가 된다. 즉, 개인정보에서 개인이 누구인지 알 수 없게 하지만 임상에는 도움이 될 수 있는 데이터로 만드는 것이다. 문제는 제대로 제거했는지 확인하지 못한 상태에서 다른 기관에 임상 데이터를 넘기는데 개인정보가 제거되지 않은 상태로 넘어갔을 때 우리에게 넘어온 임상 데이터가 '당신의 개인정보가 포함되었다' 라고 당사자에게 알려준다면 환자의 의료 정보를 수집한 기관에서 제대로 데이터의 관리를 하지 않았다는 것을 동시에 알리게 된다.

데이터는 흐름이기 때문에 그 흐름에서 누구의 책임인지 찾는 것은 의외로 쉬울 수 있지만 그때 누가 어떤 책임을 가지며 어떤 처벌을 받을 수 있는지는 신중하게 생각해야 한다. 개인정보가 포함된 임상 데이터를 받았을 때 신고하면 신고한 기관은 책임을 면할 수 있다고 해도 그 데이터를 전달해준 기관은 자동으로 책임을 지게 되기 때문이다. 그래서 이런 실수를 제거하기 위해서라도 데이터와 개인정보를 구별하고 정의할 수 있는 방법이 필요하다. 앞서 설명한 것처럼 데이터를 통해서 개인정보를 찾아내는 일을 인간보다 기계가 잘 할 수 있다면 반대로 받은 임상 데이터에서 개인정보가 포함되어 있는지 확인하는 방법도 인간보다 기계가 더 잘 할 수 있을 것이다. 기계에게 임상 데이터를 받게 되었을 때 알 수 없는 환자가 누구인지 알아낼 수 있다면 알아낼 때 단서가 되는 데이터를 제거해서 개인정보가 사라진 임상 데이터로 만들면 되기 때문이다.
역설적으로 데이터에서 알아낼 수 있는 수많은 개인정보들도 기계가 잘할 수 있지만 동시에 개인정보를 찾아낼 수 있는 심지어 그 단서까지도 포함해서 개인정보를 잘 처리할 수 있는 역할을 기계가 잘할 수 있다는 점이다. 이를 응용한다면 사람이 검색과 수작업을 통해서 찾아내고 판단해야 하는 개인정보를 기계가 스스로 학습해서 개인정보를 효과적으로 제거할 수 있다. 가장 대표적인 예는 지도 서비스에서 나오는 수많은 차들이나 사람들의 얼굴 그리고 개인정보로 노출 될 수 있는 많은 개인정보들을 자동으로 흐리게 만들어서 알 수 없도록 하는 것이다. 앞서 예를 들었던 환자의 의료 정보들도 의학적 의미를 살릴 수 있는 수준까지 임상 데이터를 살리고 그 외에 불필요한 정보가 무엇인지 인간보다 더 잘 판단해서 제거할 수 있게 된다.
Human, citizen, ... Identity ...
인간에 관한 권리에 대해서 하나의 문장으로 정리하기 시작한지 그렇게 오래되지 않았다. 정말 반세기 전에는 흑인, 백인이 분명히 구별되어 차별받았던 시절이였고 여성의 참정권이 보장된 것도 그리 오래되지 않았다. 자신이 선택할 수 없는 내용으로 차별을 받지 않아야 한다는 소극적인 형태의 차별금지를 떠나서 자신의 신념, 생각과 같이 스스로 선택했던 것이 인류에 해를 줄 목적이 아니라면 그 어떠한 생각조차도 차별의 대상이 될 수 없다고 해도 여전히 차별과 협오의 시대를 살고 있다. 그러나 조금씩 그 의미에 대해서 고민하고 공론화되면서 다양한 분야에서 그런 차별의 요소를 줄이고자 하는 노력들은 분명 인류의 진보라고 믿게 된다.
예전에는 상상하기 힘들었던 동성애의 사랑을 이제는 드라마에서 쉽게 볼 수 있고 (대한민국은 여전히 아니지만...) 그런 삶의 모습도 우리의 주변에서 일어나는 일들이라고 긍정적으로 받아들일 수 있게 되었다. 그래서 현대 사회에서의 인권이란 우리의 상상력이 어떻게 작용하냐에 따라서 그 범위가 달라질 수 있다. 사회의 변화 이제는 기술의 변화로 인간의 삶이 달라지고 그 결과 얻어지는 모습들이 달라지기 때문에 그런 변화에서 만들어지는 다양한 인권의 범위도 확대해야 하는 것이 사실이다. 그러나 종종 기술이 만든 다양한 모습에 법이 따라가지 못하는 경우를 보면 법이나 규제가 가져야 하는 유연성에 대해서 적극적으로 고민해야 할 시점이라고 본다.

인간에 대한 인권만으로 설명하기 힘들어서 국가 사회에서 시민으로 가지는 권리로 시민권을 생각하게 되었듯 기술의 발달로 만들어지는 개인정보와 데이터에 대한 고민을 통해서 인간이 데이터없이 살아갈 수 없는 그리고 그 데이터로 피해를 보고 때로는 이득을 보는 현실 세상에서 개인정보에 대한 범위까지 포함할 수 있는 정체성을 가지는 자아로 설명될 수 있는 어떤 권리 장전이 필요한 시점이라고 느낀다. 많은 경우 진보적인 생각을 가진 이들과 그런 생각이 필요없는 기득권 사이에서의 계급투쟁으로 얻어지고 그 과정에서 많은 희생이 필요했던 것도 사실이지만 분명 필요한 것은 변화하는 모습에 대해서 어떤 모습의 인간이 더 행복할 수 있는 가능성이 높은지 고민하는 과정일 것이다.
그 과정 속에서 기계 혹은 인공지능으로 대변되는 기계 기술이 영화 터미네이터 (1984) 에서 그려지듯 인간을 억압하는 존재가 아니라 인간의 권리와 확대되는 정체성을 보호할 수 있는 장치로 작용할 수 있기를 바란다. 그리고 그런 작업에서 인간보다 기계가 넓은 범위에서 더 잘 할 수 있다면 기계학습을 통해서 개인정보를 어떻게 보호할 수 있을지 고민하는 것도 필요하다고 본다. 그리고 어쩔 수 없이 수많은 데이터 속에서 작업해야 하는 인간에게 그런 개인정보를 보호할 수 있는 도구로 인공지능이 활용된다면 인간의 직업을 빼앗는 인공지능이 아니라 인간이 특별히 고민하지 않고 좀 더 창의적인 내용에 더 투자할 수 있도록 잡일들을 처리해줄 수 있는 조력자로 인공지능이 존재하고 인간의 직업을 차지하는 역할이 아닌 인간의 작업내용을 더 효율적으로 처리할 수 있도록 도와주는 존재가 될 것이라고 본다.
그렇게 인공지능이 인간에게 도움이 될 수 있는 존재가 될 수 있기를 바란다면 우선 데이터와 개인정보로 넘쳐나는 현실에서 신경쓰이는 수많은 데이터 처리와 개인정보 보호의 역할을 충실하게 수행할 수 있는지 그렇게 도와줄 수 있는 기술의 형태는 어떻게 되어야 하는지 생각해야 할 것이다.












































